


































































































































Abstract
The following contribution deals with the automated assurance of software requirements quality. There are many ways to check the content of the software requirements manually – inspections, reviews, walkthroughs, etc. However the attempt to automate the checking of requirement specifications has only come up in the past years as a result of the progress in automated natural language analysis. Text processors are now able to parse natural language texts and that makes it possible to also parse requirement documents. The three main objectives of automated requirement analysis are a) to check the requirements document against a set of rules, b) to measure the quantity, quality and complexity of the requirements and c) to extract test cases for requirements-based testing. Automated text analysis is a means of fulfilling these goals. The author began work on this subject as early as 2001 in a project in Vienna to test a large scale investment banking system against its requirements and has been working on it ever since. It is a fascinating and challenging field of study. Now many other researchers throughout the world are involved with this subject and the current state of the technology is very promising. In this paper, that state will be presented together with the experience that the author has made in the past 10 years.
1. The Nature of Requirements Documents
There have been many approaches to formalize requirement specification in the past going back to the 1970s with the RSL language. That language was the basis of the first requirement engineering system – RXVP for Requirements Evaluation and Verification Package – developed for the American ballistic missile defense system in 1975. That system had a built- in quality assurance which included consistency and completeness checks, as well as measures of specification size and complexity (Alford, 1977). For that particular project the formalized requirement approach was used successfully. Another less formal approach to specifying software requirements was introduced by Parnas at about the same time for the U.S. Navy A7 fighter bomber project. The requirements specified here included three dimensional mode/state/action tables to describe the events, prototypes to describe the user interfaces and constraints to define the non-functional requirements. A data model described the data objects and their relationships to one another. The whole document contained over 350 pages and took two years to produce. The project itself was not a resounding success but the requirement document became a model for writing requirements in a structured, semiformal mode (Parnas, 1977).
While this work was going on at the U.S. Defense Department, researchers in various universities and research institutes were also involved in developing formal requirement specification languages. Notable examples of this early work were the Z language developed by a team at Oxford University and the Vienna Definition Language – VDL – developed at the IBM research center in Vienna (Wing, 1990). Both of these languages were used successfully in specifying project requirements for selected research projects. These are only a few of the many research projects devoted to the formalization of requirements writing. Yet, the truth of the matter is that with some notable exceptions, formalized requirements writing was never accepted on a wide scale in industry. Even the semi-formalized requirement approaches such as the Parnas A7 approach have never become wide spread. That makes measurement and assessment of the requirements very difficult despite attempts to try and normalize them (El Emam, 2000). The quality assurance agent must make the best with the documents he gets. This also presents a formidable challenge to the application of automated analysis techniques.
There could be several reasons for this lack of formalization. One reason is that the original formal specification languages like VDM, Z and SETL were mathematical notations which were difficult to learn and even more difficult to apply (Hall, 1990). In their MIT project on programming automation, Rich and Waters discovered that writing formal specifications is more difficult than writing programs, since they are at a higher level of abstraction (Rich & Waters, 1988). Those persons in industry who are responsible for writing requirements are generally domain experts and not mathematicians or computer scientists. Another reason is that formal languages are restricted in scope. They only apply to a limited domain and cannot be readily adapted. Like programming languages, formal specification languages require a lot of time to write correctly, time which most requirement writers do not have. Testing and debugging are more appealing than writing rigid requirements. Unlike programming languages, specification languages cannot be readily compiled and executed. There is no way to test whether the specified algorithm is right or not without converting it to code. Therefore, there is a delay in getting a feedback (Wiegers, 2005). That is one of the arguments for agile development as put forth in the agile manifesto (Beck et al., 2002).
For this and other reasons, requirement documents remain for the most part informal, consisting of diagrams and natural language texts. People think in terms of their natural language and this is how they most easily express themselves. The overall functional architecture of the system, i.e., the business processes and the business data can be described with process models and entity/relationship diagrams , the business goals can be described with semi-formal notations such as ibis, KAOS and MaP, the business rules can be formulated in a semi-formal language like OCL but the requirements are described in prose text (Pohl, 2007). The best to hope for in regards to the quality of requirements is to get the requirement writer to structure the document in such a way that it can be readily analyzed. Of particular importance is that the analyst should distinguish between the problem and the solution. The problem is best described as a list of functional and non-functional requirements. The solution is best described in terms of use cases using templates to specify the use case attributes. Since use cases fulfill requirements, implement business rules and process business objects, they should have references to these entities. Each requirement or wish should have a unique identifier and be traceable thru the system. The requirements themselves are usually written in some form of structured natural language (Rupp 2011).
Today requirement documents are classified by their degree of formality and structure. In her book on requirements engineering Susan Robertson distinguishes between:
- Structured and unstructured requirement documents
- Informal, semiformal and formal requirement documents (Robertson, S. & Robertson, J., 1999).
In practice most requirement documents are unstructured and informal. This is one of the main reasons why so many software projects fail (Ewusi-Mensah, K., 2003). There have always been some good requirement documents, especially in the military realm where standards are enforced, but in industry requirements have not received the attention they warrant. Only in recent years have requirement documents started to become more structured and increasingly formalized. The initiative to certify requirement engineers is helping to promote better quality requirement documents. However, there are still different opinions as to the structure and content of requirement documents. Proponents of requirements engineering claim that as a minimum the requirements should be structured and semiformal, i.e. the requirements should be numbered or at least identified, functional and non-functional requirements should be distinguished from one another and the elementary functions should be described as use cases (Pohl, K. & Rupp, C., (2009).
2. Checking the Quality of Requirement Documents
The need to control the quality of requirement documents was seen already in the 1970’s by Boehm and others. In a much cited article Boehm demonstrates that the earlier defects are uncovered, the cheaper it is to remove them. The costs of correcting requirement errors in production are 10-20 times greater than the costs of correcting them at the time the requirements are written and requirement errors account for at least 40% of all errors (Boehm, 1975). This is the main justification for investing in the quality assurance of the requirements. Of course, the requirements cannot be tested, but they can be analyzed and checked for consistency and completeness. The first work on controlling textual requirement documents goes back to the 1970s when Gilb proposed reviewing requirement documents according to a specific set of rules (Gilb, 1976). At the same time Fagan at IBM was introducing inspection techniques not only for inspecting code but also for inspecting requirement documents. (Fagan, 1986). In the Ballistic Missile Defense Project Alford was leading a tool supported effort to verify the correctness of the requirement nets (Alford, 1977).
Some years later in 1984 Boehm published an article on the verification and validation of requirement documents at TRW (Boehm, 1984). Like much of what Boehm wrote, this article became an inspiration to all those responsible for ensuring the quality of requirement documents. According to Boehm and his associates at TRW there are four basic criteria for checking requirement specifications. These are:
- Completeness,
- Consistency,
- Feasibility and
- Testability.
According to this early work of Boehm “Completeness” is the degree that all of the system elements are described. There should be no TBDs, no nonexistent references, no missing attributes, no missing functions and no missing constraints. “Consistency” is the degree to which the descriptions coincide with one another. If an object is referenced by a function, then that object should also be defined. There should be no unsatisfied references, no contradictory relationships and no missing links. Boehm emphasizes the importance of traceability. “Feasibility” is the degree to which the requirements can be implemented within the planned time and budget. The number of functions and the level of quality must remain within the limits set by the cost estimation. Also the risks involved should not exceed the estimated risk limits. “Testability” is the degree to which the system can be tested with a minimum of effort. That means that there should be a limited number of external interfaces, a limited number of data exchanged and a limited number of possible states. To be testable a requirement document should be well structured and have a minimum set of structural elements.
In 1990 Martin and Tsai expanded the earlier inspection techniques by introducing N-Fold inspection for requirements analysis (Martin & Tsai, 1990). The requirements inspected were those of the Amtrak rail traffic control system. The inspection teams used the checklist approach suggested by Fagan. The crux of this wide scale experiment was that each team finds different faults, since each team has another view of the problem. Each team alone detected less than 15% of the known faults, but by joining the results of all teams more than 70% of the faults was reported. This only confirms the old saying that more eyes see more than one. It also confirms that potential errors in the future software system can be recognized already in the requirements if those requirements are structured, as they were here, and one looks close enough.
Victor Basili and his associates at the University of Maryland picked up the early work of Boehm, Gilb and Fagan and began experimenting with it to demonstrate how effective inspection methods are in finding defects in documents. The experiment was done on the requirement specification of the cruise missile. For it they used several groups of students using three different inspection methods – ad hoc, checklists and scenarios. Using scenarios to systematically walk through the functionality turned out to be the most effective way of discovering defects. Using checklists helped to discover minor defects and formal errors in the construction of the requirement document, but it was even weaker than the ad hoc method in detecting serious problems. The scenario-based approach could detect up to 45% of all known faults, the ad hoc method 31% and the checklist-based method only 24% (Basili, et al., 1995). This indicates that simulation of the application solution proposed in the requirements is the best approach to finding serious faults. Applied to modern day business requirement documents, that means walking through the business processes and their use cases.
Boehm continued his work as a professor at the University of Southern California, where he pursued a number of research projects, one of which was on discovering conflicts in non-functional requirements. It is known that software quality goals can conflict with one another. For instance, runtime performance can conflict with usability as well as with reliability and security. Testability can conflict with performance and usability. Portability can conflict with usability, performance and maintainability. The goal of the research reported on in 1996 was to use a knowledge base and automated extraction of the non-functional requirements to identify quality requirement conflicts. The method was applied to the requirements for the National Library of Medicine – MEDLARS – and was astoundingly successful. Over half of the quality problems that later came up in operating the system could be detected as the result of contradictory requirements. Most of these contradictions could not be recognized by the human eye, but in using automated techniques to process the requirement texts, they were detected. The significance of this research is that it introduced for the first time, the automated analysis of textual requirements (Boehm & Hoh, 1996).
In recent years, work on the automated analysis of requirement documents has exploded.. The term “Text Mining” is used to denote the technology of extracting information from natural language texts. Several papers have been published and a book written by T. Miller published on the techniques of text mining (Miller 2005). Some approaches first convert the text to a markup language as done at the University of Madrid (Sierra et al., 2008) whereas others extract information from the text directly (Hayes et al., 2006). In either case, the result is information which can be further processed to determine the quality of the requirement document. Advanced tools even recognize contradictions and missing attributes as well as violations to the rules of requirement writing (Sneed, 2007).
It may not be possible for a quality assurance agent to judge the quality of the business solution. That can only be done by a domain expert in reviewing the document. It is the task of quality assurance to ensure that the description of the proposed business solution is precise, complete and consistent. One should not forget that most errors which later come up in the software are not because of implementing the wrong solution, but because of implementing the right solution wrong. The majority of errors found in system testing are errors of omission, i.e. something is missing which should be there. That was the finding in the Clean Room approach to quality assurance (Sheerer, 1996). The cause of such errors is inadequate requirement specifications. The missing function, data or link was already missing in the requirements document, only it was not noticed there among the several hundred pages of monotonous text. By putting that text in a structured, marked up format the contradictions and missing elements become more obvious. Besides, that makes it possible to use text parsers to analyze the texts, thereby relieving the human controller of the boring task of checking each and every entity attribute and cross reference.
Completeness and consistency checks as well as the test of preciseness can and should be automated. For instance, it is possible to check if an object is input or output to some use case and that a use case has at least one input and one output. Furthermore it is possible to automatically check if all required attributes of a use case are defined, if every business rule is applied in at least one use case and that every use case fulfills at least one requirement. Inversely, it can be confirmed that every functional requirement is fulfilled by at least one use case. Incompleteness and inconsistency are signs that the business solution has not been thought through. In addition, it is possible to automatically check the preciseness of statements in that they conform to the rules of requirement writing. The requirement document needs to be brought up to a minimum quality level before it is accepted for implementation and automated analysis can help achieve this. By submitting documents to an automated requirement checking tool, a significant number of potential errors can be detected, in particular those errors that result from an incomplete and inconsistent description (Wilson et al., 1997).
3. A Schema for structuring Requirement Documents
If requirements cannot be formalized, then the least one can expect is that those texts be structured and marked up. The IEEE Standard 830 offered a general scheme for structuring requirement documents. It is not very detailed, but it can serve as a starting point. The latest version of that standard requires the document to be structured according to functions and constraints. The constraints define how the system has to be constructed. The functions define what has to be accomplished by the system. Each application function is listed out independently of when and where it is executed together with its inputs and outputs. These inputs and outputs are to be found in a special section on the data model. Since functions may also contain sub functions and sub-sub functions this listing out of functions results in a functional hierarchy, in which each elementary function is a functional requirement. Thus the 830 standard is primarily focused on specifying what has to be done, as opposed to how it is to be done. The non-functional requirements, or constraints, provide some guidance to the technical implementation, but they do not provide a logical solution (IEEE, 1998).
A more recent standard for ensuring the quality of requirements is the ISO/IEC 25030 (Boegh, 2008). This standard combines the ISO/IEC-9126 on quality modeling with the ISO/IEC 14598 for software product evaluation. Rather than restricting itself to software, the new standard takes a holistic view of the proposed system including hardware, software and data. For assessing the quality of a system the quality characteristics of ISO/IEC-9126 are applied. These are divided into internal and external qualities. External qualities are those that are perceived by the users of the system, i.e. the functionality, usability, reliability and efficiency. Internal qualities are those that are perceived by those responsible for the maintenance and further development of the system, i.e. the maintainability, reusability, portability and testability. The external qualities are determined by testing the system whereas the internal qualities are assessed through analysis of the code and documents (ISO, 1994).
The essence of the 25030 standard is the table of contents prescribed for requirement documents. It foresees six main chapters and three annexes.
The main chapters are:
- Scope
- Conformance
- Normative references
- Terms and definitions
- Quality requirements framework
- Quality requirements
The annexes are:
- Normative terms and definitions
- Requirement analysis processes from ISO/IEC 15288
- Bibliography
The quality requirements are broken down into:
- General requirements and assumptions
- Stakeholder requirements
- Software requirements (ISO, 2002).
Software requirements should be stated in such a form that can be readily verified as being fulfilled or not fulfilled. Here the standard distinguishes between what and how. The “what” is the result of the requirements definition process, the “how” is the result of the requirements analysis process. These two processes are described further in the ISO/IEC 15288 standard on process quality assurance (ISO, 2007).
The standards cited here are of a general nature as they apply to a whole host of application types. For any particular application type they must be adapted and refined, but the basic principles should remain. In a requirement document for common business applications, the “what” is expressed as a wish list of functions and quality characteristics. The “how” is a description of the proposed logical or business solution, that is, how is the system to be constructed in order to fulfill the requirements imposed. The “what” identifies the goals, the functions required, the data required and the minimum quality characteristics. The “how” identifies the business data objects processed by the system, the system interfaces with the human actors and other systems, and the events that occur – the use cases. The resulting requirements document should be a hierarchical structure of the problem and the business or logical solution without going into technical implementation details (El Emam & Birk, 2000).
At the top of the requirement hierarchy are the business goals followed by the requirements themselves – a list or table of functional and nonfunctional demands on the proposed system. Here it is important to check that every requirement is associated with some goal. This problem description defines what has to be done. It is followed by a business solution description depicting how it is to be done. The solution description should include as a minimum, a list of the business objects, a list of the system and user interfaces, a set of use case specifications in the form of standard templates and a list of business rules. The solution description can be checked for completeness and consistency. Every use case should process at least one object and serve at least one interface. It should be triggered by an actor or an event, it should have pre and post conditions, it should have at least two paths – a positive and a negative one, it should have in each path a sequence of steps, and it should be fulfill at least one requirement. There may also be associations between use cases, associations such as usage, extension and inclusion. If there are, then they should be reciprocal.
Use Case descriptions have become quite common in describing detailed solutions, but one should remember that a use case is a solution and not the problem (Cockburn, 2002). A use case denotes a particular usage of the target system for the purpose of fulfilling one or more requirements. In some business process models it is referred to as an event. (Scheer, 2005). t occurs at a given place at a given time and is triggered by a human actor or another use case. The use case – Produce_Sales_Report – is a solution to the problem of producing a sales report at the end of each month. Since use cases fulfill one or more requirements they should have links to the requirements they fulfill as well as to the business rules they implement. These links should be built into the use case descriptions. Use cases should also be linked to a particular business process. A business process is a chain of interdependent use cases. Thus by transposition requirements are linked via the use cases to the business processes and these to the business goals.
Business-Goal -> Business-Rules -> Business-Process -> Business Requirements -> Use Case
The model of a business requirements schema is shown in the following diagram (see Figure 1).

4. Rules for checking natural language Requirements
The quality assurance of software requirement documents begins with a convention as to how the requirements are to be structured and formulated. For this there should be a set of rules and it is the task of quality assurance to ensure that those rules are adhered to. The reason for a convention is to enforce a unified form of writing requirements and to ensure that given quality criteria are met.
To begin with there should be an underlying model for the requirement document, for instance a functional model or a use case model or a combination of both. As pointed out above the document should contain both a problem and a logical solution description. In the problem description, the business goals are stated, the local business rules prescribed and the functional and non-functional requirements listed out. The business goals should be stated in such a way that they can be confirmed as being fulfilled or not fulfilled (see Table 1).
| GOAL-01 Cost Reduction | The new order entry system should reduce the costs of processing customer orders by at least 50%. |
| GOAL-02 Speed of delivery | The new order entry system should reduce the time to deliver goods to the customers from two days to one day. |
Local business rules, as opposed to global business rules, are project specific. They can be either conditional or computational rules (see Table 2).
| RULE-03 Resupply Rule | If an article item on stock falls below the minimum stock level for that item, a resupply order should be automatically generated for the amount prescribed for that article type. |
| RULE-05 Computing VAT | The VAT for each purchase is computed as the selling price * 0.19 minus the local tax rebate. |
The requirements are to be grouped by type. There are functional, non-functional and data requirements. Each requirement should be uniquely identified and explicitly stated as shown in the table of functional requirements (see Table 3).
| FUNC-REQ-02 Order Processing | The customer should have the possibility of selecting articles to be ordered. He must first enter his customer number. Then his identity and his credibility are checked. If they are ok, he may order up to 10 items at one time. If an ordered article is available on stock and in sufficient quantity, the order is to be accepted. If the article is not on stock the order is to be rejected. If the quantity on stock is too low, a back order is to be created. |
| FUNC-REQ-03 Dispatching | For every article item fulfilled a dispatch order should be generated and sent to the dispatch office. The ordered item should be sent to the customer within one day after it has been ordered. It is sent together with the order confirmation. |
| FUNC-REQ-04 Billing | For every customer order in which at least one item is fulfilled, an invoice is to be printed and sent to the customer. The invoices are to be prepared once a month at the end of the month. The invoice should include the items ordered, their prices, the total sum, the VAT and the amount due. |
The non-functional requirements should be measureable. Either they can be answered with a simple yes or no answer or they contain a number which is reached or not reached as shown in Table 4.
| NF-REQ-01 Response Time | The response time for a customer query should be <= 1 second. The response time for a customer order should be <= 3 seconds. |
| NF-REQ-02 Transaction Capacity | The system should be able to process at least 1000 orders an hour without any loss of performance. |
| NF-REQ-03 Availability | The system should be available 24 hours a day, 7 days a week, for at least 95% of the time. |
In addition, special requirements may be placed on the data such as those shown in Table 5.
| DATA-REQ-02 Customer Data Migration | The current master file for customer data should be taken over on a 1:1 basis by the new system. The file should become a relational table. |
| DATA-REQ-03 Customer Data Identifier | The primary key for the customer data is the 6 digit customer number used in the past. That number should have a control bit. |
The problem description part of a requirement document would contain as a minimum:
- a statement of business goals
- a list of project specific rules
- a list of functional requirements
- a list of non-functional requirements
- a list of data requirements.
The solution description should contain as a minimum:
- a rudimentary data model
- a list of system actors
- a set of use case descriptions
- samples of the planned user interfaces
- definitions of the required system interfaces
- a table of business rules.
The use case descriptions should contain as attributes:
- the using actor
- references to the fulfilled requirements
- the invoking trigger
- the preconditions to the event
- the post conditions of the event
- the main path with its steps
- the alternate path with its steps
- the exception condition
- the business objects processed
- the business rules applied
- references to the other use cases – extends, uses, includes.
Sample 1 shows the template for specifying use cases according to the rules defined above. This use case description goes beyond what is currently prescribed in the IREB curriculae “fundamentals” and “requirement modelling”.
| Attribute | Description |
|---|---|
| Label: | Dispatching |
| Fulfills: | Func-Req-03 - Daily Dispatching |
| Implements | Rule-06 – Dispatch Condition |
| Trigger: | EndofDay |
| Actor: | Dispatcher |
| Frequency: | Daily |
| Pre Conditions: | Dispatch order items must be available. |
| Post Conditions: | Dispatch orders are generated. |
| Main Path: | 1) Dispatcher starts dispatch job. 2) System sorts dispatch items by customer number. 3) System adds customer data to dispatch order. 4) System prints dispatch order |
| Alternate Path: | None |
| Exceptions: | System finds no customer to match a dispatch item. |
| Rules: | Dispatch orders are to be printed by customer. |
| Objects: | Dispatch items, dispatch orders, customers. |
| Inherits: | Standard-printing-function. |
| Uses: | COBOL-Wrapper |
| Extends: | Customer-order-processing. |
| Comments: | Dispatch orders are to be manually checked by the dispatcher prior to being sent to the warehouse. |
This gives the quality controlling agent, whether it be a human being or a tool, the possibility of making completeness, consistency and cross reference checks. For instance, the following checks can be made:
- if every requirement is associated with a business goal
- if every functional requirement is fulfilled by some use case
- if every data requirement is covered by the data model
- if every object defined in the data model is processed by some use case
- if every object processed is defined in the data model
- if every rule is assigned to a some use case
- if every using actor is defined
- if every invoking trigger is governed by a rule
- if every use case is defined with all of its member attributes.
A complete list of requirement checks can be found in the SoftAudit Tool Documentation at ANECON.com.tools.
5. Metrics for measuring natural language Requirements
As Tom Gilb once put it, metrics say quality better than words (Gilb, 2008). If the quality of requirements is to be evaluated, the requirements should be measured. Unfortunately, requirement measurement is still at a rudimentary state compared to design and code measurement. It is true that Gilb addressed the subject of requirements measurement in his first book on software metrics in 1976. Gilb perceived requirement documents from the viewpoint of the HIPO method as a tree structure with nodes and levels. Each elementary node was seen as a single requirement with inputs and outputs. To measure the size and complexity of the requirement trees, he suggested counting the nodes, the breath and the depth of the tree as well as the number of inputs and outputs of each node. Unfortunately Gilb’s book was published in Sweden and hardly anyone took notice of it (Gilb, 1976).
In the USA it was not until 1984 that an article appeared on the subject of requirement measurement. Boehm was concerned with the quality of the requirements and in particular with the requirement characteristics given in Chapter 2:
- Completeness,
- Consistency,
- Feasibility and
- Testability.
To measure completeness Boehm suggested counting the number of TBD’s, the number of undefined references, the number of required but missing text items, the number of missing functions, the number of missing constraints and the number of missing prerequisites. To measure consistency he proposed counting the number of contradictory statements, the number of deviations from existing standards and the number of references to non-existing documents. To measure feasibility he suggested counting the number of requirements that could only be implemented with great effort, the number of requirements whose implementation effort could not be predicted at all, the number of high risk requirements and the sum of the risk factors. To measure testability Boehm proposed counting the number of quantified non-functional requirements, the number of testable functional-requirements with a clear pass/fail criteria and the number of visible intermediate results. These counts were then compared with the total number of counted items to come up with a quality score. Of course these counts had to be done manually by a human inspector. Automated requirement measurement was at that time out of the question (Boehm, 1984).
In his book on requirements management Christof Ebert makes a case for measuring requirement documents even if they are only in natural language. He maintains that the requirements should be counted, their degree of completeness determined, the number of standards violations counted and the business value of each requirement computed. Only by quantifying the requirement quality and quantity is it possible to estimate the implementation effort and to calculate a return on investment (Ebert, 2005). If software projects are to be value driven, this is a definite prerequisite.
Ebert categorizes requirement document types as being informal, structured, semi-formal or formal. To be measurable requirements should at least be structured and contain semi-formal elements. This makes it possible for natural language text analyzers to not only count elements but also to check rules. One of the leading pioneers in this field is the author and lecturer Chris Rupp. Rupp has not only proposed how to structure natural language requirements but also how to measure them. In her book on requirements management Rupp proposes 25 rules for writing prose requirements including such rules as that all requirements should be uniquely identified and that every requirement sentence should have a subject, an object and a predicate (Rupp, 2007). She also suggests how requirements can be measured. In subsequent articles she and her coworkers have expounded upon this subject and proposed the following requirement metrics (Rupp & Recknagel, 2006):
- Ambiguity
- Activeness
- Classification
- Identification
- Readability
Unambiguousness is measured by counting the requirements written according to a predefined template so that they cannot be misinterpreted.
Ambiguity = 1 – {ambiguous requirements / total requirements }
Activeness is measured by counting the requirements that are not formulated in a passive mode. The passive sentences are without a subject, i.e. actor, such as “A report is to be written at the end of the month”.
Activeness = 1 – { passive requirements / total requirements }
Classification is measured by counting those requirements containing key words that can be used to assign the requirement to a given category. This is equivalent to indexing texts for storage in a text database.
Classification = classifiable requirements / total requirements
Identification is measured by counting the requirements with a unique identifier. In fact every requirement should have a type and a number to identify it.
Identification = uniquely identified requirements / total requirements
Readability is measured by counting those requirements which can be understood on their own merit without references to other requirements or sources of information.
Readability = 1 – {requirements with cross references / total requirements}
Mora and Denger have provided several other possible measures such as the length of requirements in words, the number of subjects or objects and the quantification of non-functional requirements. These rules are still in an experimental stage. The important thing is that work is going on to make requirements, even prose text requirements, measurable (Mora & Denger 2003).
This author has included 15 of the Rupp Rules in the tool TextAudit for analyzing German and English requirement texts. In addition to that the tool makes all of the completeness and consistency checks defined in the last section, provided that the information is available. The consistency of goals and requirements is checked, as is the completeness of the requirement fulfillment by the use cases and the data model. Use cases are checked to ensure that all of their required attributes are present. Finally no less than 50 counts are made of various requirement elements, including the size metrics - function-points, data-points and use case points. These counts are used to compute the complexity and quality of the requirement document. As a result the user receives a composite metric report in addition to a report on all requirement rule violations (Sneed, 2009).
It is true that these metrics only apply to the requirement document itself and not to the proposed solution, but there is a definite relation between the quality of the document and the quality of the solution proposed therein. The author has served as an expert witness in several court cases involving software project failure, including a case that was taken to the European court of arbitration. In all cases, the cause of the failure was the inadequate requirement specification and in all cases this was obvious in the structure and content of the requirement document. An incomplete, inconsistent and poorly written requirement document is an obvious sign of an inadequately specified IT-system (Van Lamsweerde & Letier, 2000).
6. Tools for checking the Quality of natural language Requirements
Regarding tools for the automated quality assurance of software requirements, one must distinguish between tools which process formatted requirement specifications stored in tables, xml documents or requirement databases such as RequisitePro from IBM and tools which process plain texts. There are numerous tools of the former type on the commercial market but these tools are proactive in nature. They force the requirement writer to formulate the requirements in a specific way. A good example is RAT – the Requirements Authoring Tool from the ReUse Company in Madrid. RAT uses a set of agreed upon boilerplates and leads you, step by step, suggesting the next term of your requirement always ensuring the right grammar. While guiding the user RAT collects some useful metrics on what that user is writing, including the detection of inconsistences, coupling requirements, ambiguous requirements, non-atomic requirements, use of the wrong verb tense, mode or voice, consistent use of measurement units, etc. This is a practical approach provided the requirements are not written yet. It forces the user to work in a prescribed template. [see: www.reusecompany.com].
The second category of tools, to which SoftAudit belongs, presumes that the requirements have already been written. The most that can be done is to add key words or markup the document. These tools presume some kind of natural language processing – NLP. Significant progress has been made in the past years in parsing natural language texts, making it possible to recognize grammatical patterns and to count grammar types. Text mining has become a frequently cited technique used for extracting selected information from all kinds of text [Mille, 2005]. It is obvious that this technique can also be applied to natural language requirement texts. Mora and Denger have reported on their work in automatically measuring requirement documents [Mora & Denger 2003] and in the ICSE proceedings of 2007 there is a contribution from Wilson, Rosenberg and Hyatt on the automated quality analysis of natural language requirement documents [Wilson, 2007]. Wilson’s tool uses nine quality indicators for requirements specification: Imperatives, Continuances, Directives, Options, Weak Phrases, Size, Specification Depth, Readability and Text Structure. At the 2008 conference on requirements engineering Castro, Duan, Cleland and Mobasher from the DePaul University presented a promising approach to text mining for soliciting requirements [Castro et al. , 2008].
This early research proves that natural language text analysis is coming along but that it is still in the experimental phase. The Sophist GmbH has developed such a tool but up until now it has only been used internally in projects. Most of the other tools of this type have remained at the universities or research institutes where were developed. An exception is the Requirements Assistant offered by IBM. [see: http://www.requirementsassistant.nl]. This tool was developed to aide reviewers in reviewing a requirement document in interactive mode. It analyzes the text sentence by sentence and highlights contradictory and unclear terms. It can also track cross references if they are really satisfied. The human reviewer is practically guided through the text. The emphasis is less on measuring the requirements as it is on reviewing the structure and content of the requirement for deficiencies. To this end, it is very useful but it presupposes a human reviewer who has the time to go through the requirements step by step. The persons responsible for estimating the costs of a project based on the requirements will prefer a tool which can provide a quick and cheap insight into the overall size, complexity and quality of a requirement document before the manual reviewing process begins. This of course does not preclude a manual review. That is still necessary, but only after the decision has been made to proceed or not.
That tool which comes closest to what is described here was developed within a research project at the Concordia University in Montreal. It is part of a bigger project aimed at applying NLP techniques to the RE process. The tool not only classifies sentences but also extracts values of features – indicators – likely to make a sentence ambiguous or unambiguous in terms of service understanding using a metric for the degree of difficulty. The Feature Extractor tool then feeds the sentences one-by-one to the Stanford Parser for POS tagging and syntax parsing. In so doing, the values of the indicators are counted for each sentence. In the end the NLT requirement document is graded according to its understandability, conceptual consistency and its adherence to formal rules. This approach of Olga Ormandjievaia and her associates at Concordia is a very promising approach to measuring the quality of requirements in terms of their unambiguity and comprehensibility. [Ormandjieva 2007].
A similar tool has been proposed by Fabbrini and his associates at the University of Pisa in Italy. That tool with the name QuARS - Quality Analyzer for Requirements Specification”. syntactically parses natural language sentences using a MINIPAR parser. The quality indicators are based mostly based on specific keywords, rather than on more general classes of words. In this respect, it is similar to the tool described here [Fabbrini 2001].
In summary, it can be stated that there are now a number of tools to choose from for analyzing natural language requirements, however they are all goal and context dependent. The right choice depends on what information one wants to get out of the requirements, for what purpose, and how the requirements are formulated. There are many factors to be considered.
7. Automated natural language Requirement Analysis – a Case Study
With the advent of automated text analysis and text mining techniques, it has now become feasible to automatically process requirement documents. What used to take weeks to accomplish can now be done in a few minutes. Automated text analysis has opened up several new possibilities for assuring the quality of requirements, among them:
- Automated model checking
- Automated rule checking
- Automated measurement and
- Automated test case extraction.
The requirement document used for this study was taken from an EU funded research project for developing a collaboration platform for small businesses. It was a 144 page English text describing the goals, prerequisites and constraints of the project as well as the 90 functional and non-functional requirements of the software product. In addition, some 22 use cases are defined in tabular format and elaborated in activity diagrams (Pernul, 2009). This document is typical of semiformal requirement documents using a mixture of text and diagrams to specify the requirements.
The tool used for this study was EngAudit, a member of the SoftAudit tool family for checking and measuring software artifacts – texts, models, sources and test cases. EngAudit was developed to process English language documents. There is a sister tool GerAudit for processing German language documents. The basis for both tools is a natural language parser – NLP – which cuts the text up into sentences and analyzes one sentence at a time, recognizing the grammar tokens - nouns, verbs, adjectives, etc. Prior to analyzing the selected text the user must convert the pdf text into pure text format and define the key words for identifying the major semantic elements such as goals, rules, requirements, objects, interfaces and use cases. After that the text is scanned to select all nouns which are displayed to the user in a noun list. It is then the task of the user to select the relevant nouns and to delete the others from the list.
When parsing the text only those sentences are processed which contain at least one relevant noun. The text parser cuts the text up into statements and checks each statement against the deficiencies which the user has selected. The deficiencies are classified as major, medium and minor deficiencies. The English statements are classified as actions, states or rules. For consistency checking internal tables are built up for the entity types to be cross-checked against each other, for example which requirement is fulfilled by which use case. At the same type the various word and statement types are counted, as to how often they occur. The results are:
- An excel table of requirements and rules cross-reference table of all nouns used and where they are used
- A table of logical test cases.
- An XML model of the objects, use cases and rules
- A rule violation report
- A requirement metric report
The requirement table is used for cross checking the requirements against the data and use case models. The noun cross-reference table points for each noun to those statements where that noun is referenced. The logical test case table ensures that there is a test case for every action, state and condition specified. With the XML model of the objects, use cases and rules the consistency and completeness of the proposed business solution is checked. The rule violation report identifies all violations of the selected rules for structuring and writing requirements. The metric report presents a summary of the size, complexity and quality of the requirement document.
The Requirement Deficiency Report is a log of rule violations and discrepancies listed by document. There are all together 40 rules checked including 12 of the Rupp rules. The violations are classified as major, medium and minor. The deficiency text is given out together with the section and the sentence in which the deficiency occurs. This is to help the user in finding the discrepancies in the requirement document. At the end the weighted sum of the deficiencies is computed to give the requirement conformance rate. An excerpt from the requirement deficiency report for the business project is given in Sample 2.
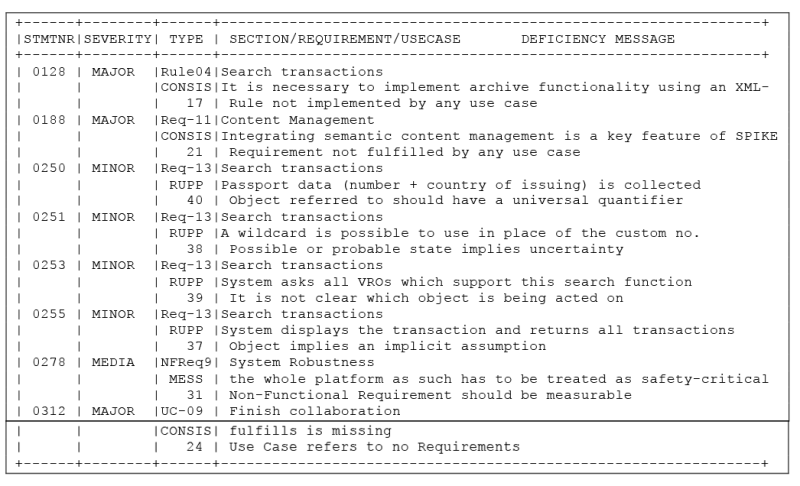
The Requirement Metric Report lists out the size, quantity, complexity and quality metrics. At the end, the requirement deficiency metrics are summarized. There is a report for each requirement document as well as a report for the system as a whole. The structure of the report is as follows:
- Quantity Metrics (32)
- Size Metrics (5)
- Complexity Metrics (5)
- Quality Metrics (5)
- Deficiency Metrics (5)
The sample requirement metric reports from this requirements document produced for an EU research project on internet communication platforms. They indicate a below average requirement quality of 0.454 mainly because of the incompleteness of the document, the lack of testability and the non-conformance with the rules for requirement writing (Pernul, G. et al., 2009).

All of these documents can be produced within minutes. However, the preparation of the automated analysis may take several hours. As pointed out above, users must insert key words into the structured document to identify requirement elements such as goals, rules, triggers, actors, interfaces, etc. Then they must create a table to associate the keywords with the predefined elements of the tool. After that, the document is scanned to identify all of the nouns, i.e. potential objects. For this the tool uses a dictionary. In German it is relatively easy to recognize nouns, but in English there are compound nouns like “bank savings account” which have to be concatenated into a single term. Furthermore in English many nouns are also verbs. These have to be identified in an exception list. All in all, the English language is very poor for parsing purposes as compared to the German language which is more precise. After the nouns have been identified and stored in a noun table, the user must go through that table and eliminate those nouns which are not relevant to the application. Only after these prerequisites have been fulfilled, is it possible to start the automated requirement analysis.
8. Benefits of Requirement Quality Analysis
The question comes up as to what are the benefits of requirement metrics and what consequences should be taken from the deficiency reports? In the case of the deficiency report, the answer is clear. It is intended to be the basis for a requirement review. It brings to light the obvious formal weaknesses in the requirement document so that the document reviewers can concentrate on the essential problems in the content of the document. If there are many formal deviations from the standards, this indicates that the requirement document should be revised before it can be accepted. In addition, the deficiency report has an educational purpose. It shows the requirement writers what they have done wrong so that they can improve their requirement writing skills. Just as programmers learn from code deficiency reports, requirement engineers need a feedback on the quality of their work.
In the case of the requirement metrics, there is no direct benefit to the requirement engineers, other than to compare their scores on one document with the scores on another. The benefits are more for the product owners or project managers. The requirement specification is the main source of information for making project cost estimations (Sneed, 2014) Object-points, function-points and use case points are standard size measures taken from the requirement document to project the size of the software to be developed. Normally they would have to be counted manually but here they are automatically derived from the requirement document. The complexity metrics can be useful in assessing the costs of requirement engineering. They indicate requirement bloat and redundancy, for instance if the size of the text is appropriate to the content contained therein. The quality metrics are indicators for the degree of ripeness the requirement document has attained. If the document has low completeness and consistency ratings it is a sign that it is not really finished. The incomplete and inconsistent text parts will have an effect on the quality of the product as a whole. A low changeability metric indicates that the document will be more costly to maintain. The testability metric is an indicator for the effort required to test the system. A system with many conditional actions requires more test cases than a system with mainly unconditional actions. Finally, the conformity metric shows to what degree the requirement writers have followed the prevailing rules. Rules can be crossed out, then they will not be checked, but those rules which are kept should be adhered to. The degree of conformity to the rules is the best indicator for the uniformity of requirement documents, provided that is a goal of the user organization.
9. Future Prospects in automated Requirement Quality Analysis
The progress in automated text analysis, i.e. text mining, has opened up a host of opportunities to better control the quality of requirement documents. It does not alleviate the necessity to have a manual review of the requirement, but now this review can concentrate on the content (Parnas & Weiss, 1995). The checking of formalities can be done by a tool. Besides that an analysis tool can provide essential measures for assessing the quality of the document and for estimating implementation costs. Up until now software measurement has been focused on the design und code. Now it can be extended to the requirement documents. Defining new requirement metrics above and beyond what has been described in this paper will become an important part of the software measurement field. There will also be a tighter connection between requirements and testing. Now that it has become feasible, more and better test cases with links to the business objects, processes and rules, will be taken automatically from the requirements and fed into the test case data base. There is still a gap between the logical test cases and the physical test data, but in time, this gap too will be overcome and it will become possible to validate a system directly against its requirements (Sneed, 2008).
In the future more requirement analysis tools will appear on the scene. At the moment they are more in an experimental stage. Requirement metrics need to be calibrated based on feedback from the projects where the tools are used (Selby, 2009). In addition, the requirement writing rules need to be extended and more precisely checked. There is a definite need for more research on how to measure and assure the quality of requirements. In respect to Lord Kelvin, only when we are able to express the quality of requirement documents in numbers, will we be able to compare and assess them (Kelvin, 1867). There is an even greater need for research on how to estimate project costs based on the requirements. The costing methods currently propagated are far from being mature. Therefore, this work can only be seen as a first step in trying to measure the quality of requirements.
References
- Alford, M. (1977). A Requirements Engineering Methodology for Realtime Processing Requirements. *IEEE Trans. On S.E.*, Vol. 3, No. 1, Jan. 1977, p. 60
- Basili, V. et al. (1995). Comparing Detection Methods for Software requirements Inspections – A replicated Experiment. *IEEE Trans. on S.E.*, Vol. 21, No. 6, June 1995, p. 563
- Beck, K. et al. (2001): “Manifest für Agile Softwareentwicklung”,
, 2001 - Boegh, J. (2008). A new Standard for Quality Requirements. IEEE Software Magazine, March 2008, p. 57
- Boehm, B. (1975). The high costs of software. In *Practical Strategies for developing large Software Systems*, Ed. E. Horowitz, Addison-Wesley, Reading MA., 1975, p.3.
- Boehm, B. (1984). Verifying and Validating Software Requirements. *IEEE Software Magazine*, Jan. 1984, p. 75
- Boehm, B. & Hoh I. (1996). Identifying Quality Requirement Conflicts, *IEEE Software Magazine*, March, 1996, p. 25
- Castro-Herrera, C.,Duan, C., Cleland-Huang, J., Mobasher, B.: Using Data Mining and Recommender Systems to facilitate large-scale, Open and Inclusive Requirements Elicitation Processes, *Proc of 16th Int. Conference on Requirements Engineering*, IEEE Computer Society Press, Barcelona, Sept. 2008, p. 33
- Cockburn, A. (2002). *Agile Software Development*. Addison-Wesley, Reading, MA.
- Ebert, C. (2005). *Systematic Requirements Management*. dpunkt.verlag, Heidelberg
- El Emam, K. & Birk, A. (2000). Validating the ISO/IEC 15504 Measure of Software Requirements Analysis Process Capability. *IEEE Trans. on S.E.*, Vol. 26, No. 6, June 2000, p. 541
- Ewusi-Mensah, K. (2003) *Software Development Failures*. M.I.T. Press, Cambridge
- Fabrinni, F., Fusani, M., Gnesi, S., and Lami, G., “An Automatic Quality Evaluation for Natural Language Requirements,” Proceedings of the Seventh International Workshop on Requirements Engineering: Foundation for Software Quality REFSQ'01, Interlaken, Switzerland, June 4-5, 2001.
- Fagan, M. (1986). Advances in Software Inspections. *IEEE Transactions on Software Engineering*, Vol. 12, No. 7, Juli 1986, p. 744.
- Gilb, T. (1976) *Software Metrics*, Studentenlitteratur. Lund, Sweden,
- Gilb, T. (2008) Metrics say Quality better than words. *IEEE Software Magazine*, March 2008, p. 64
- Hall, A. (1990). Seven Myths of Formal Methods. *IEEE Software Magazine*, Sept. 1990, p. 11
- Hayes, J. et al. (2006). Advancing Candidate Link Generation for Requirements Tracing. *IEEE Trans. on S.E.*, Vol. 32, No. 1, Jan. 2006, p. 4
- IEEE (1998). ANSI-IEEE Standard 830: Recommended Practice for Software Requirement Specifications. *IEEE Standards Office*, New York
- ISO (1994). ISO/IEC Standard 9126: Software Product Evaluation. *International Standards Organization*, Genf
- ISO (2002). ISO/IEC 15288: Information Technology – Life Cycle Management – System Life Cycle Process. *Int. Organization for Standardization*, Genf
- ISO (2007). ISO/IEC Standard 25030-2007: Software Engineering – Software Product Quality Requirements and Evaluation (SQuaRE) – Quality Requirements. Int. *Organization for Standardization*, Genf
- Jacobson, I. et al. (1992). *Object-oriented Software Engineering – A Use Case Driven Approach*. Addison-Wesley. Reading, Ma.
- Kelvin, W.T. (1867). Treatise on Natural Philosophy. *British Encyclopedia of Science*, Glasgow
- Martin, J. & Tsai, W.T. (1990) N-Fold Inspection – A Requirements Analysis Technique. *Comm. Of ACM*, Vol. 33, No. 2, Feb. 1990, p. 225
- Miller, T.W. (2005). *Data and Text Mining – A Business Application Approach*. Prentice-Hall, Upper Saddle River, N.J.
- Mora, M. & Denger C. (2003). Requirements Metrics. *IESE-Report No. 096.03/*Version 1.0, October 1, Brüssel
- Ormandjieva, O., Hussain, I., Kosseim, L.: “Toward a Text Classification System for the Quality Assessment of Software Requirements Written in Natural Language“, Proceedings of *SOQUA'07*, September 3-4, 2007, Dubrovnik, Croatia
- Parnas, D. (1977). The use of precise Specifications in the development of Software. *IFIP Congress-77*, Toronto, Sept. 1977
- Parnas, D. & Weiss, D. (1995). Review Techniques for assessing Requirement Quality. *Comm. Of ACM*, Vol. 38, No. 3, March, 1995, p. 319
- Pernul, G. et al. (2009). Analyzing Requirements for Virtual Business Alliances – the case of SPIKE, *Int. Conf. on Digital Business (DIGIBIZ 2009)*, London, UK, June 2009
- Pohl, K. (2007). *Requirements Engineering*. dpunkt.verlag, Heidelberg.
- Pohl, K. & Rupp, C. (2009). *Basiswissen Requirements Engineering*, Aus- und Weiterbildung zum Certified Professional for Requirements Engineering Foundation level nach IREB-Standard. dpunkt.verlag, Heidelberg
- Porter, A., Votta, L., Basili, V. (1995). Comparing detection Methods for Software requirement Specifications – A replicated Experiment. *IEEE Transactions on S.E.*, Vol. 21, No. 6, 1995
- Rich, C. & Waters, R. (1988). The Programmer’s Apprentice. *IEEE Computer Magazine*, Nov. 1988, p. 19
- Robertson, S. & Robertson, J. (1999). *Mastering the Requirements Process*, Addison-Wesley, Harlow, G.B.
- Rupp,C. & Recknagel,M. (2006). Messbare Qualität in Anforderungsdokumenten. *Objektspektrum*, Nr. 4, August 2006, p. 24
- Rupp,C. (2007). *Requirements Engineering and Management*. Hanser Verlag, Munich/ Vienna
- Rupp, C. & Cziharz, T. (2011). Mit Regeln zu einer besseren Spezifikation. *Informatikspektrum*, Vol. 34, No. 3, 2011, p. 255
- Sierra, J. et al. (2008). From Documents to Applications using Markup Languages. *IEEE Software Magazine*, March, 2008, p. 68
- Scheer, A.-W. (2005). *Von Prozessmodellen zu lauffähigen Anwendungen* – ARIS in der Praxis. Springer Verlag, Berlin, 2005
- Sheerer, S. et al. (1996) Experience using Cleanroom Software Engineering. *IEEE Software Magazine*, May 1996, p. 69
- Selby, R. (2009). Analytics-driven Dashboards enable leading Indicators for Requirements and Designs of Large-Scale Systems. *IEEE Software Magazine*, Jan. 2009, p. 41
- Sneed, H. (2007). Testing against natural language Requirements. *7th Int. Conference on Software Quality (QSIC2007)*, Portland, Oct. 2007
- Sneed, H. (2008). Bridging the Concept to Implementation Gap in Software Testing. *8th Int. Conference on Software Quality (QSIC2008)*, Oxford, Oct. 2008
- Sneed, H. (2009). *The System Test*, Hanser Verlag, Munich/Vienna
- Sneed, H. (2014). Anforderungsbasierte Aufwandsschätzung. *GI Management Rundbrief* – Management der Anwendungsentwicklung und –wartung, Vol. 20, No. 1, April 2014, p. 62
- Van Lamsweerde, A. & Letier, E. (2000). Handling Obstacles in Goal-Oriented Requirements Engineering. *IEEE Trans. on S.E.*, Vol. 26, Nr. 10, Oct. 2000, p. 978
- Wiegers, K. (2005). *More about Software Requirements – thorny issues and practical advice*. MicroSoft Press, Redmond, Wash.
- W. M. Wilson et al. (1997). Automated Quality Analysis of Natural Language Requirement Specifications. *19th Int. Conference on Software Engineering (ICSE2007)*, Montreal, May 2007, p. 158
- Wing, J. (1990). A Specifier’s Introduction to Formal Methods. *IEEE Computer Magazine*, Sept. 1990, p. 8.

Harry M. Sneed has a Master’s Degree in Information Sciences from the University of Maryland, 1969. He has been working in the IT field since 1967 when he started as a FORTRAN programmer for the US Navy Department. He migrated to Germany in 1971 and worked first for the Federal University Administration and then for Siemens in the database area. In 1978 he set up the first commercial software test laboratory in Budapest. There he developed the first German requirements engineering tool SoftSpec in 1982. That tool was used to document the requirements in many large German organizations, including BMW, Bertelsmann, Thyssen Steel and the German Railways. That tool was used not only to collect and store the requirements on the mainframe, but also to check the completeness and consistency of the requirements, as well as to generate a system design.
At the end of the 1980’s Sneed moved over to the field of reverse and reengineering and became involved in projects throughout Europe. In 2009 he received the Stevens Award from the IEEE Computer Society for his pioneering achievements in that field. He conducts courses at two technical colleges and two universities. He has published over 400 technical articles and written 23 books on the subjects of software testing, maintenance, migration and measurement. His work in requirement engineering is mainly in connection with reverse engineering, change management and test, three areas in which he still works as freelance consultant.
Comments (1)
First of all, I liked this article too much, very formal and well structured, the author's quality is noticed.
I just wonder, why today with all the advance in ML and text recognition, stuff like this is not widely used? Why agile approach of user stories e.g. in a Scrum way are more popular? I guess that there is an increased need in software requirements quality process rather than requirements specifications, What do you think?