







































































































































The Challenge
Towards Knowledge-Based and Requirements-Centric Quality Assurance
Information systems embody knowledge about organizations. In a software project, several points of view, perceptions and expectations about the system knowledge continuously coexist. Pursuing the alignment between such views is still a key software Quality Assurance challenge in many present-day projects that impacts on success rates and costs [1]. Such alignment has been widely discussed in the literature [2-6].
Managing system knowledge in a structured form as explicit requirements specifications (represented by textual documentation, models, etc.) may contribute to address this challenge [7]. Requirements specifications provide a crosswise basis for the discussion, negotiation, management and validation of system knowledge.
Structured validation of explicit requirements specifications allows pursuing an agreement on a common system knowledge representation that is shared by all involved roles in the context of a requirements-centric strategy [8]. Requirements-centric projects are based on the observation that requirements play a central role for many software activities that work on the same system: developers and maintenance engineers need to know which will be the functional knowledge to be considered when developing or maintaining the system-to-be [7]; quality assurance engineers and testers need to know the requirements of the system-as-is [7] to be checked with the previously defined requirements; transformational projects need to know current requirements in order to analyze future improvements, etc.
In environments in which requirements specifications either do not exist, are not maintained (they cease to be valid after changes), lack sufficient quality [9,10] or are not shareable across the project, technical debt [11] and knowledge loss risks may appear, since knowledge is not specified in accessible artifacts and becomes spread over different minds that may become inaccessible or unavailable. Not addressing such risks may lead to extra costs due to rework (relearning/recovery of knowledge, harder communication or knowledge transfer difficulties). This is the main challenge to be addressed by the application of the solution presented in this article.
Aligning Requirements Specifications and Tests
We propose managing system knowledge together with tests by obtaining and maintaining a requirements model that represents the functional knowledge of the system that needs to be validated by tests, and reacting when the tests or the model change or cease to be aligned.
In this way, requirements validation is continuously performed. Validation implies checking the conformity with user needs (correctness) [9,10] and, consequently, pursuing the absence of contradictions (consistency) that may lead to conflicts. As in scientific progress, absence of contradictory views is the basis for acceptance and progress. In software engineering, we also need to detect contradictory views and resolve them as soon as possible, taking requirements management as a base to support this task. Otherwise, requirements conflicts arise. This is why the alignment between different requirements specifications and validation tests is a current challenge. As stated in [4], “Weak alignment of requirements engineering (RE) with verification and validation (VV) may lead to problems in delivering the required products in time with the right quality”. Moreover, as observed in [5], “rich interactions between RE and testing can lead to pay-offs in improved test coverage and risk management, resulting in increased productivity and product quality”.
Requirements specifications also need to be maintained as the business evolves, because evolution modifies the perceptions and expectations of stakeholders. The maintenance of requirements specifications is a critical factor in order to preserve its usefulness [10]. Non up-to-date documentation rapidly decreases in its usefulness and credibility. Checking the alignment between artifacts that represent system views and reacting to detected misalignments are necessary activities to support the evolution of specifications. Moreover, traceability between requirements artifacts [9] is essential to propagate changes to dependent artifacts and maintaining their consistency.
In this article, we focus on the alignment between tests and functional requirements models [12], by pursuing continuous validation and traceability. Checking this alignment as a continuous quality activity is aimed at enhancing the maintenance of up-to-date specification artifacts (models and documentation) and test cases, linking them as a base for improving knowledge reuse and retention, reducing rework [11,13], addressing automation opportunities and systematic testing [14], and providing a basis for better communication and negotiation throughout a project [7].
The presented approach also pursues the shift-left anticipation of testing in development and maintenance projects [15]. Shifting left the design of test cases in the software process (even before the system is developed or changed) helps thinking in advance on how we will validate the system once it is implemented or evolved and it improves the quality of requirements specifications. In this way, the strong relationship [12] between requirements and tests is enhanced.
Testing Goes Further Than Reporting Errors
Testing needs to be requirements-based [12,14,15] since testing cannot be effectively performed without knowing what the system is expected to do. In other words, improving requirements management has a positive influence on testing. When explicit requirements specifications are missing, unavailable or not mature enough, testers need to recover the system knowledge by experimentation [3]. Therefore, testing professionals incrementally become system experts. Based on this observation, we present the Recover approach, which has the following objectives:
- Structured and knowledge-based design of test cases.
- Test-driven generation of structural and behavioral models [16] that recover the functional system knowledge acquired by testers.
- Up-to-date evolution of requirements models in alignment with test cases.
- Maintenance of test cases when models are changed according to business knowledge evolution.
- Automatic generation of functional requirements documentation.

In this article, we briefly describe Recover and we comment on its value and limitations. The Recover approach is supported by a tool which is able to simulate the execution of test cases on an incrementally generated model, as a means to automatically check their alignment. The model specifies functional requirements in a structured way. The structured language used to represent both structural and behavioral knowledge of the system is the Unified Modeling Language (UML) [17] which is a de facto standard modeling language.
The overall framework of the research is that of design science [18]. The problem we try to solve is twofold: 1) the integration of knowledge management in functional testing by recovering a requirements model, and (2) the maintenance of the alignment between the requirements model and the test cases as the system evolves. The problem is significant because many projects do not consider explicit requirements specifications as crosswise artifacts aimed at enhancing knowledge management for development, maintenance, QA activities or transformational projects. Moreover, as far as we know, there are no environments to explicitly support the alignment between tests and requirements models by execution simulation. Our approach inherits the main advantages of the popular Test-Driven Development (TDD), but applied in the development and maintenance of functional models aligned with test cases [16]. We have evaluated our method by means of two case studies: a mobile application of an airline company and the online website of a bank.
The Approach
Figure 1 illustrates the overview of the Recover environment, which evolves testing services approaches by including knowledge management (grey zone) in a systematic and assisted way.
In current testing projects, test cases are designed and specified in diverse (more or less structured) formats. The design is based on the particular knowledge that each tester possesses. Then, test cases are (manually or automatically) executed on the System Under Test (SUT) and verdicts are obtained [19].
In Recover, test cases are used to automatically assist the iterative test-driven specification [11] of the acquired knowledge and continuously validate it, by executing the tests on the model to check their alignment. Moreover, documentation on the technical requirements of the system may be generated, updated and shared across the organization.
In the following, we describe the core features of Recover and we illustrate them by using a running example based on an e-commerce testing project.
Tests Design and Specification
Test cases are designed in a structured, knowledge-based form, as a sequence of object-oriented steps. Test cases are composed by a fixture (a set of objects with attribute values and links among them that describe an initial configuration of the system); the occurrence of operations that change the state; and assertion expressions that check the satisfaction of an expected statement (formalized as a query expression) in a particular state. Additionally, test cases may be structured in test suites that share a common fixture.
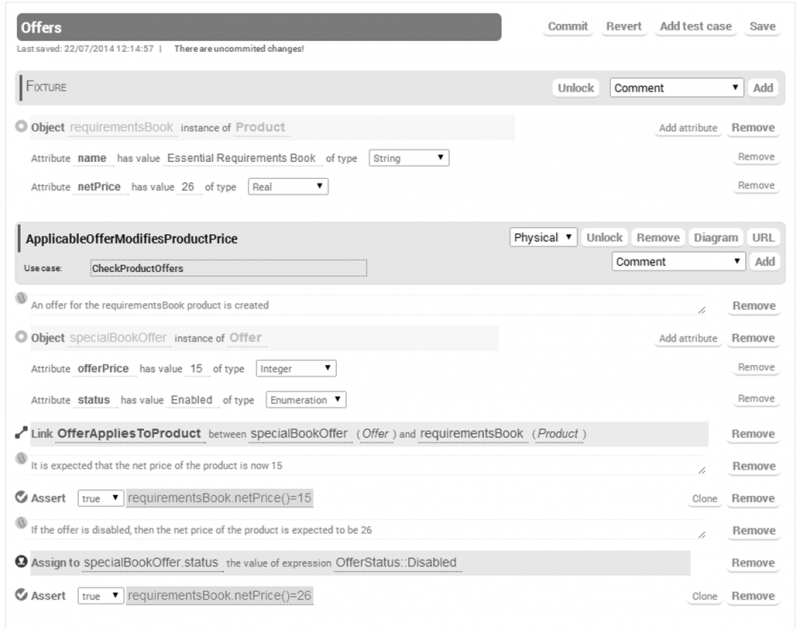
Figure 2 shows a screenshot of the test case ApplicableOfferModifiesProductPrice. In the fixture we have defined a product requirementsBook that costs 26 (we assume that prices are expressed in a defined currency). The test case checks that if we set an enabled offer (object specialBookOffer) with price 15, and this is linked (instance of the association OfferAppliesToProduct) to requirementsBook, then it is expected that the visible net price of this product (defined by the query operation Product::netPrice()) should be 15, instead of its original price. If we disable the offer, the net price is expected to become 26 again.
Test-Driven Evolution of the Model
Recover test cases have the property that they may be automatically executed on the (incrementally generated) model. In each execution, Recover checks the following question: “Does the model specify the necessary and valid knowledge to correctly execute the test cases?” The verdict to this question may be Pass (all required knowledge is specified in the model), Error (some required knowledge is not specified) or Fail (some specified knowledge does not produce the expected results).
In each execution, if the model does not have the valid knowledge to correctly execute the test cases, then the error/failure information suggests applicable changes to make the model valid according to new required knowledge. The Recover environment implements automatic reactions to errors in order to evolve the model automatically.
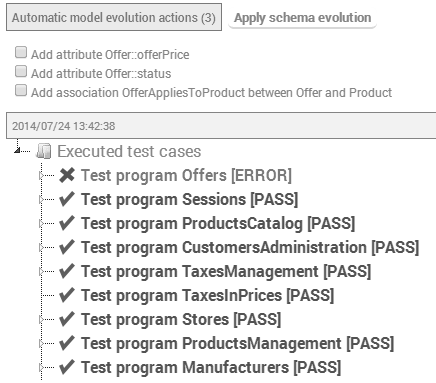
In Figure 3, we can see that the current model is aligned with all test cases except for the test case ApplicableOfferModifiesProductPrice. The reason for the misalignment (as indicated by the information provided by Recover) is that the concept Offer is not yet specified in the model, and consequently the execution of this test case cannot be correctly simulated. Based on this information, Recover suggests automatic actions to evolve the model. In this example, our environment automatically adds (see Figure 4) the class Offer with attributes offerPrice::Integer and status::OfferStatus, the enumeration OfferStatus with literals enabled and disabled, and an association between Product and Offer (OfferAppliesToProduct).
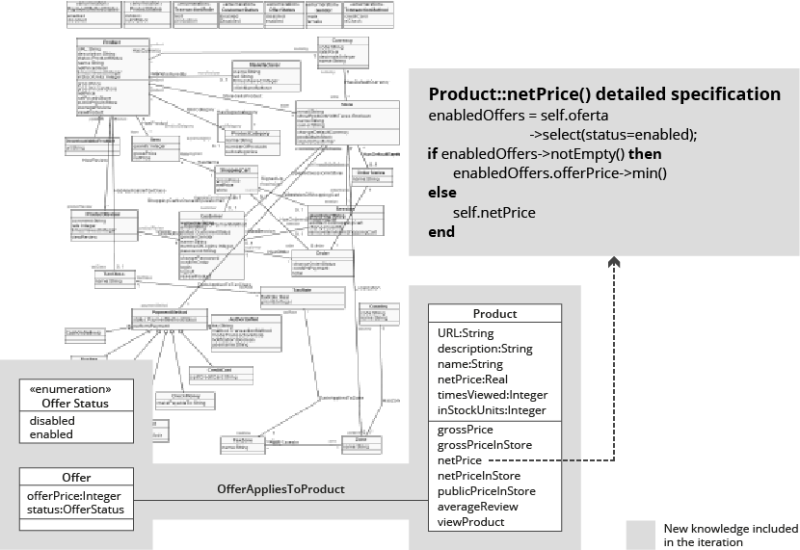
At this point, if we execute again, the first assertion shown in the test case of Figure 2 fails because the operation Product::netPrice() (which defines how the visible net price of a product is obatined) does not take into account the effect of offers on the price computation. Therefore, the operation needs to be updated in order to return the offered price if an applicable offer for the product has been defined.
After these changes, the model now includes the new acquired knowledge represented in Figure 4, in addition to the already defined knowledge. The added knowledge does not have lateral effects with previous test cases because the verdict of all tests remains Pass.
Documentation Generation
When test cases and the model are aligned, technical documentation of the functional requirements of the system can be automatically generated. As the test cases and the model evolve, new versions of the documentation can be obtained in order to have a common and up-to-date repository of knowledge.
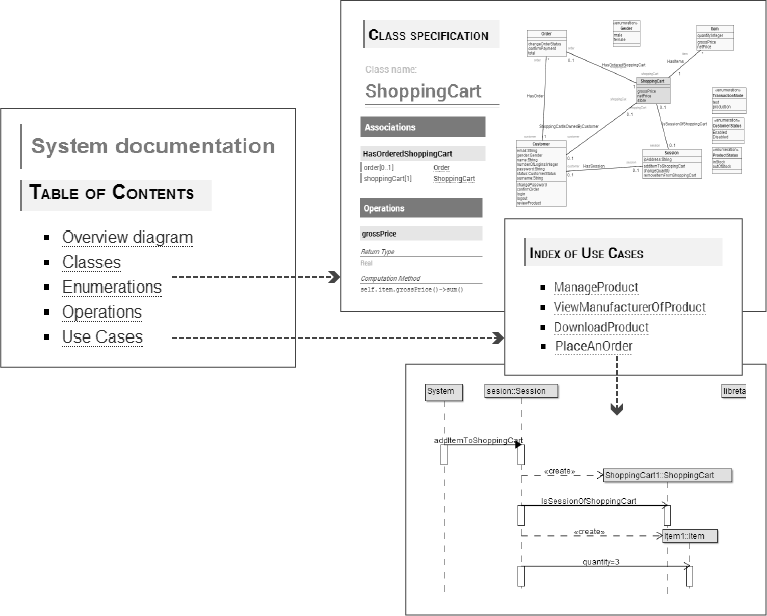
The documentation is generated as navigable HTML pages and it includes 1) Focused UML structural diagrams [17] for each concept, 2) a detailed description of the characteristics that describe each concept (represented as attributes and associations), 3) the definition in technology-independent pseudo-code of the operations, which describe the behavioral capabilities of each concept (see Figure 4 for an example), 4) the list of use cases, including traceability to their associated tests, and 5) UML sequence diagrams for each test case scenario.
Figure 5 shows screenshots of the generated technical documentation and some of their traceability relationships.
Continuous Validation Process
Figure 6 shows the continuous validation process assisted by Recover. The approach is applicable both for projects where no functional requirements model exists (the model will be empty in the beginning and it will be recovered) or those where some initial model is available (the model will be maintained and evolved based on changes).

The execution without errors of a set of test cases on the current model indicates that the test set and the model are aligned. At this point we are able to generate a valid version of the documentation (see Section Documentation Generation) that contains the knowledge required by the test cases.
If we add or update a test case and the execution fails, a misalignment is detected and needs to be resolved. The cause of the error may be an erroneous expectation (then we know which test cases need to be fixed) or the evidence that new test cases require the model to specify or update knowledge (see Section Test-Driven Evolution of the Model). In the case that a new or updated test case does not produce any error or failure, it means that it does not require adding/modifying knowledge, although it provides more confidence on the already specified requirements.
The approach also allows managing business changes and analyzing their impact on existing test cases. Consider, for example, that the login operation that defines how a customer signs in the system is modified according to a business rule change. If we execute the test cases on the modified model, Recover will point out those test cases that no longer pass and the cause that produces this misalignment in the test case specification. Non-passing test cases are those that need to be refactored, since they are proven to be affected by the system knowledge change (see Figure 7).

Once a new alignment situation is achieved, then a new version of the documentation may be generated and made public to the stakeholders.
Lessons Learned and Limitations
Recover is a continuously improved solution that results from a design-science research process [18]. Its application in case studies has been the basis for making improvements and detecting limitations to be considered in future work. In the following we briefly comment on the experience acquired in two real-world projects: (1) the testing project of a new airline mobile app aimed at assisting checking-in, viewing and changing reservation data, and searching flight status; and (2), the testing project for an online bank system aimed at managing business and private accounts for different types of products offered by the bank. Table 1 shows the summary of the lessons learned through these case studies.
| Case study | Lessons learned | Recover improvements |
|---|---|---|
| Airline mobile app |
|
|
| Bank online website |
|
|
The application of the approach has the following limitations: 1) Object-oriented knowledge is required for the structured design of test cases; 2) test cases need to be defined in a structured form and, therefore, less ambiguity is accepted in comparison with non-restricted natural language. It implies detecting conflicts earlier and investing effort to solve them, which usually becomes a benefit later.
The resultant functional requirements model also has limitations to be considered: 1) it is specified by using a subset of the Unified Modeling Language [17], complemented with OCL expressions in order to formalize constraints and behavior definitions. Therefore the model audience needs basic knowledge of this language in order to understand it. Moreover, the current implementation of the supporting tool does not include the ability to deal with some UML model constructs: n-ary associations when n>2; graphical attributes multiplicity (they need to be expressed as complementary OCL constraints); and association classes (they may be specified as normalized binary associations); 2) the resultant model represents, in each iteration, the knowledge that is required for the processed test cases. The more exhaustive the testing activity, the more validated the resultant model.
Finally, the approach inherits the main limitation of alignment strategies, which as practical validation may fail in the case that all views are invalid at the same time. However, pursuing the quality of software is a continuous task of checking alignment between relative truths (stakeholders’ expectations, perceptions, the current version of explicit specifications, the system behavior, etc.). Even the system implementation cannot be considered an absolute truth, because it usually rapidly becomes unaligned with other validation references over time (changing requirements, new expectations, unrevealed necessities, etc.).
Conclusions and Future Work
In this article we have described the main characteristics of the Recover approach, which allows the Test-Driven Generation, continuous validation and up-to-date maintenance of system functional models and technical documentation in alignment with tests. Based on our current application experience, we have observed that Recover may have the following benefits: 1) test case design is based on a knowledge-structure that promotes structured thinking; 2) a functional model aligned with test cases is recovered and maintained by executing tests on the model and reacting to changes that cause misalignments; and 3) updated technical documentation is made available as the testing projects make progress.
The associated Recover tool is continuously improving as an ongoing project. As future work we mention five areas of improvement: 1) extending the catalogue of automatic model evolution actions; 2) adding more auto-completion facilities in the test editor to improve test cases specification; 3) enriching the model expressivity with n-ary associations and association classes; 4) providing extended integration facilities for existing test management solutions; and 5) extend customization characteristics for the generated documentation.
The presented approach contributes to software quality assurance in projects that realize the necessity of enhancing knowledge management, and extends the role of testing projects further than reporting errors. Furthermore, it is based on a systematic approach and a tool that supports its efficient application.
Recover is a problem-based innovation solution. First, it provides functional models and documentation if they don’t exist. Therefore, it covers a basic necessity for better knowledge management, which is a common challenge in organizations lacking quality functional specifications. Moreover, it provides functional models as a resultant added value of the testing process, which can be used for most of the activities that have the system as work subject. Additionally, the resultant model may contribute to the application of Model-Based techniques that were not previously applicable. Second, it facilitates the maintenance of tests, models and documentation, by providing misalignment-based reactions aimed at preserving the value of up-to-date specifications. Finally, test cases that need to be updated according to model evolution are detected. This supports the test refactoring process, which is an important activity that consumes critical time in many testing projects.
References
- [1] The Standish Group, CHAOS Manifesto. Think Big, Act Small. 2013.
- [2] Larson, J., Borg, M. Revisiting the Challenges in Aligning RE and V&V: Experiences from the Public Sector, in: Proceedings of the 1st International Workshop on Requirements Engineering and Testing, 2014.
- [3] Hartmann, H. Testers Learning Requirements, in: Proceedings of the 1st International Workshop on Requirements Engineering and Testing, 2014.
- [4] Bjarnason, E., et al. Challenges and practices in aligning requirements with verification and validation: a case study of six companies. Empirical Software Engineering (2013): 1-47.
- [5] Damian, D., Chisan, J., An empricial study of the complex relationship between requirements engineering processes and other processes that lead ot payoffs in productivity, quality, and risk management. IEEE Transactions in Software Engineering 32.7 (2006): 33-453.
- [6] Post, Hendrik, et al. Linking functional requirements and software verification. In: Proceedings of the 17th IEEE International Requirements Engineering Conference, 2009. RE'09. IEEE, 2009.
- [7] K. Pohl, Requirements Engineering: Fundamentals, Principles, and Techniques. Springer. 2010.
- [8] A. Olivé, Conceptual schema-centric development: a grand challenge for information systems research, in: Proceedings of CAiSE 2005, LNCS, Springer, 2005, pp. 1–15.
- [9] O.I. Lindland, G. Sindre, A. Solvberg, Understanding Quality in Conceptual Modeling, IEEE Software 11 (1994) 42–49.
- [10] IEEE Computer Society. IEEE Standard 830-1998. Recommended Practice for Software Requirements Specifications. 1998
- [11] Gartner & Cast Software, Whitepaper: Monetize Technical Debt. Available online: http://www.castsoftware.com/resources/document/whitepapers/monetize-application-technical-debt, 2011.
- [12] R.C. Martin, Tests and Requirements, Requirements and Tests: A Möbius Strip. IEEE Computer Society. 2008.
- [13] E.Roodenrijs, R. Marselis, The PointZERO® vision. Sogeti, 2013.
- [14] E. Roodenrijs, L. Aalst, R. Baarda, B. Visser, J. Vink. TMap NEXT® - Business Driven Test Management. UTN. 2008.
- [15] Graham, Dorothy. Requirements and testing: Seven missing-link myths. Software, IEEE 19.5 (2002): 15-17.
- [16] A. Tort, A. Olivé, M. R. Sancho, An Approach to Test-Driven Development of Conceptual Schemas. Data & Knowledge Engineering 70 (2011) 1088-1111.
- [17] OMG, Unified Modeling Language (UML) Superstructure Specification, Version 2.4.1, formal/2011-08-06, http://www.omg.org/spec/UML/2.4.1/, 2011.
- [18] von Alan, R. Hevner, et al. Design science in information systems research. MIS quarterly 28.1 (2004): 75-105.
- [19] OMG, UML Testing Profile, Version 1.2, formal/2013-04-03, http://www.omg.org/spec/UTP/1.2/, 2013.

Albert Tort is the Research&Innovation Solutions Lead in Sogeti Spain. During the last years, he has been working as Quality Assurance and Software Control & Testing specialist in several projects for customers in different sectors (banking, airlines, insurance, procurement, etc.). Furthermore, he has been the lead of research&innovation projects developed at Sogeti. He was the winner of the “Capgemini-Sogeti Testing Innovation Awards 2015” for the submission of the best individual entry "Recover: Reverse Modeling and Up-To-Date Evolution of Functional Requirements in Alignment with Tests. He is also a member of the SogetiLabs community.
Previously, he served as a professor and researcher at the Services and Information Systems Engineering Department of the Universitat Politècnica de Catalunya-Barcelona Tech. As a member of the Information Modeling and Processing (MPI) research group, he focused his research on conceptual modeling, software engineering methodologies, OMG standards, knowledge management, requirements engineering, service science, semantic web and software quality assurance. Currently, he is also the coordinator of the postgraduate degree in Software Quality Assurance of the School of Professional & Executive Development of the Technical University Of Catalunya (BarcelonaTech).
He obtained his Computer Science degree in 2008 and he received his M.Sc. in Computing in 2009. In 2012 he presented the PhD thesis “Testing and Test-Driven Development of Conceptual Schemas”. He is the author of several publications in software engineering journals and conferences.