







































































































































Basic Concepts of Software Estimation
To get started with the subject of software estimation, I recommend an excellent book [2]:
“Software Estimation: Demystifying the Black Art” by Steve McConnell published in 2006.
Nothing from this classic work became obsolete over the last decade. It is a must-read for everybody in the industry.
I will start with re-iterating some concepts introduced by McConnell and then will expand to other topics based on my own project experience.
It is relatively straightforward to estimate parameters of existing physical objects, such as the height of a tree. Things get more complex when estimating something in the future, which does not yet exist. For the same tree – how tall will it grow in 5 years? And even more complicated if an estimated variable depends on the efforts we will apply in the future. Typically: efforts/time needed to implement a requirement or a set of requirements. Here it is crucial to distinguish between the following concepts:
Estimate is a prediction or judgement. For example: We can be ready in 4-6 weeks.
Target is a statement of a desirable business objective. For example: We need to deliver a release before the holiday season starts.
Commitment is a promise (possibly contractual). For example: The release shall be delivered by Nov 1st.

A typical issue with estimates, when people ask you about the estimate, is that they are actually more interested to get a commitment from you, possibly because of a target they have.
Another important fact about estimates is that they are not simple numbers, they are probability distributions. If you say, the height of a tree in 5 years will be 4.52m, are you 100% sure? 60% sure? What is the probability that the tree will grow between 4.5m and 4.6m? How different is the probability that the tree height will be between 4m and 5m? It is much more useful to specify a range and provide a probability of the target parameter being in that range. E.g. I am 90% sure the tree height will be between 4m and 5m.
The figure below shows a typical probability distribution for software estimates. For any specific value on the X-axis there is a corresponding probability on the Y-axis. There is a natural lower limit for the estimates, where the probability becomes zero (the project cannot be completed any earlier). But there is no upper limit, since the work can take any amount of time, although with decreasing probability. Some point on the X-axis is the nominal outcome – the one with a probability of 50%.
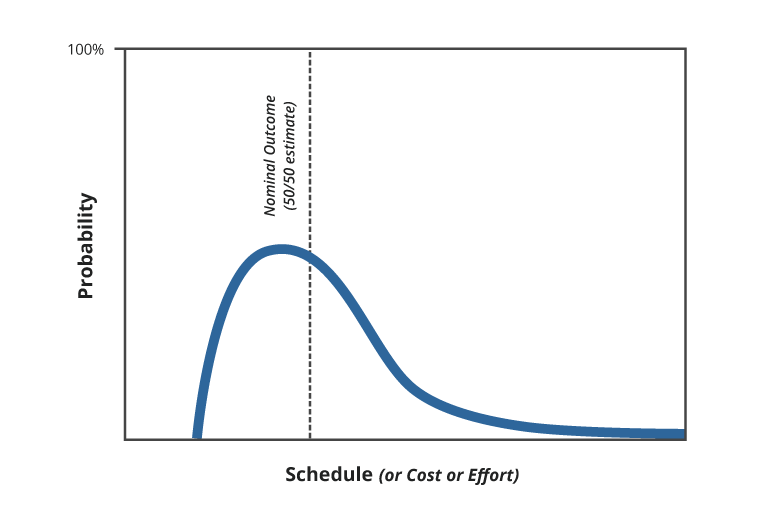
The difference between the estimate’s accuracy and precision is another thing that I would like to point out here. An estimate expressed as an interval is accurate if the estimated parameter really lies in the specified range (between 4m and 5m in the example above). Precision is a length of the interval (1m in the above example). We want our estimates to be accurate in the first place, and only then as precise as possible. A typical issue is having a very precise, but inaccurate, estimate: “a project will take 4-5 weeks” (for a project, which will take 3 months!). Accuracy can solely be assessed in retrospect, when the real value of the estimated variable is known. Precision can be defined a priori.
The book [2] describes and discusses in detail very useful estimation techniques, which are beyond the scope of this article.
Estimates and Project Control
For me the main statement of McConnell’s book [2] is the following:
“Once we make an estimate and, on the basis of that estimate, make a commitment to deliver functionality and quality by a particular date, then we control the project to meet the target.”
Let us explore this statement in more detail.
We are usually asked for estimates when a new project is being negotiated with a customer, its requirements have been elicited and documented (input), and now an estimate is needed to be able to set the price (output).
Even though the relationship between the price towards the customer and an internal effort estimate can be complex, there is a clear correlation. Once the contract is granted (“after signature”), the project starts and the commitment made cannot be changed anymore (without substantial negotiation efforts).

For the project team the price from the contract is now binding and becomes part of the input, not the output.
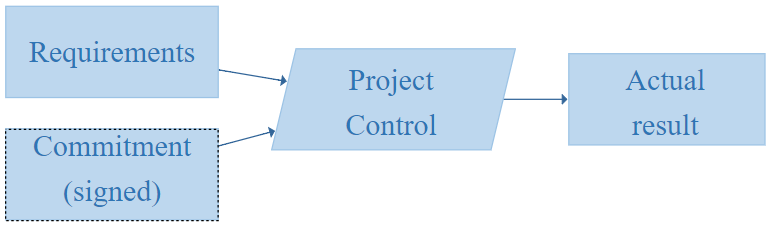
The project team must control the project in such a way that the cost (actual spent effort) stays below the signed commitment. Now it is no longer about an accurate estimate, but about a profitable project.
Interestingly, the other input parameter – the requirements – which were supposed to be fixed during estimation, should now be treated in a more relaxed manner, because interpretation of the requirements and different design choices will have a significant impact on the financial result.
This all may sound obvious, but many inexperienced teams automatically set on fulfilling the promised requirements as the most important goal and lose their sight of the costs until the project turns into a loss.
The project team can (and should) perform a re-estimation of the remaining scope in the beginning (and possibly also during the project). However, it is not useful just to know that you predict to end up with 300K in costs in a 210K fixed price project. You must be alarmed and take all necessary countermeasures to get the project under control.
The actions can include, for example:
- Actively managing technical solutions, sizing them to the constraints, especially when the requirements are not too detailed.
- Actively managing customer expectations.
- Actively monitoring the scope and claim change requests (CR) to get additional funding in case of a scope increase.
- In the worst case, re-negotiating commitments with the customer.
Depending on context, sales people may pick a price, corresponding to different intervals on the estimate probability curve, because they consider business parameters, usually unknown to the technical team. When you start a project, you have to know exactly where you are in the probability distribution. If you know that your target has been set at a lower end of the estimated range, you will behave differently (much more aggressively) than if you were at the upper end of the range.
Representation of an Estimate
So far, an estimate was treated as if it were a single number (or more precisely – a single probability distribution) for the entire scope of the project. Even though such a number is important as a result of the estimation process, a useful representation of the estimate should be more elaborate.
In my experience, an estimate should be represented as a table with a feature breakdown, where each row in a table represents a feature (or sub-feature). There can be one or two breakdown levels (more is possible, but not practical). A comment column can capture the assumptions made during estimation and/or other useful information.
It is not important, what kind of feature breakdown structure is used here. It can be anything that agrees well with the other parts of the project, e.g. requirements specification, and helps to understand the estimate.
In most cases such a breakdown for the estimate will not be shared with the customer, but it will help the supplier organization to better understand the estimates. It will demonstrate the relative weight or risk of individual features, provide some traceability to requirements documentation and give a confidence, that no area is forgotten. Such a table will also support later changes, as it will allow seeing their impact on scope, because usually only some of the features are affected.
Example:
| Feature | Efforts (man-days) | Comment |
|---|---|---|
| Feature A | ||
| Sub-feature A1 | 5.0 | |
| Sub-feature A2 | 4.5 | |
| Feature B | 2.5 | |
| Feature C | 8.0 | |
| Total | 20.0 |
The basis for estimation is a requirements document (e.g. SRS – Software Requirements Specification). If it is well structured, the breakdown for the estimate can follow the structure of the document – using its headlines, maybe, even down to individual requirements. However, in many cases the requirements document is structured in a way which makes it difficult to reuse the same structure for the estimate. In this case the estimator would create their own functional breakdown, which takes on more of the solution perspective and is built around the entities present in the solution: – its components and features.
In a complex system, with features potentially crossing multiple components, the component dimension could be added to the estimate spreadsheet to make it even more clear. If individual components are implemented by different teams, such an estimate breakdown shows not only the potential team load, but also the focus of specific features in specific components:
| Feature | Total | Component 1 | Component 2 | Comment |
|---|---|---|---|---|
| Feature A | ||||
| Sub-feature A1 | 5.0 | 5.0 | ||
| Sub-feature A2 | 4.5 | 3.0 | 1.5 | |
| Feature B | 2.5 | 2.5 | ||
| Feature C | 8.0 | 4.0 | 4.0 | |
| Total | 20.0 | 12.0 | 8.0 |
Such an estimates table can be stored in a spreadsheet, e.g. Microsoft Excel. It is important that this spreadsheet is versioned together with the related requirements specifications. Even without a sophisticated configuration management tool, a separate version of the file can be stored with a version suffix in its name, e.g. “Project_Estimate_v2.0.xlsx”. Changes between the versions can be simply indicated by colouring the changed/added rows/values. This enables all stakeholders to see how the estimates changed in relation to the changes in requirements. If needed, a version history can be kept in the same file, but on a separate data sheet.
One variant of the estimate shall be developed by the sales team during bid preparation. Beyond the pure efforts estimate it should contain the calculations explaining how the offered price is derived from the estimates. This is very helpful for future reference.
Another variant of the estimate should be prepared by the project team once it starts working on the project. The team estimate should be periodically reviewed. Deviations from the sales estimate should be discussed and aligned between the project team and the sales team; they are usually caused by different understanding of the scope and of the proposed solution. Feature breakdowns in the sales and project team’s estimates can be different, as the latter is developed using much more detailed information about the project.
Estimates in the Requirement Management Lifecycle
In the last section, I would like to talk about the timing of the estimation process.
I have often seen waterfall-thinking in the bidding process:
- We start with analysis. We talk to the customers to understand their needs. We write everything down in a long requirements document. We formulate non-functional requirements. We run multiple rounds of feedback with the customer. At the end, we get the requirements specification in an “agreed” state.
- Now we estimate the efforts based on the agreed specification.
- Further, we make a commercial proposal with a price based on the estimate.
- At last, we hope to get a signature under the contract and cannot wait to start development.
Instead, we are often surprised when a customer, after seeing the price for the first time, suddenly changes his mind, drops half of the features from the scope, changes requirements, asks you for alternative solutions and/or explanations, or in the worst case just cancels the project or turns to a different vendor.
This happens, because for the customer the value they get from our proposed solution depends very strongly on the price they have to pay for this solution. If the price is too high, they will re-think the importance of certain requirements for them. This explains why in many cases the customer asks for a price (or they also like to ask for an “estimate”) before the contractor is able to do any reasonable amount of analysis.
My take on this is that writing requirements specifications should go hand in hand with estimations and that the estimate (in a sense of a spreadsheet above) is an additional view of the specification and “estimated” is an important quality criteria of the requirements (under the aspect “agreement”). Providing a specification to your customer has a limited value without giving an idea of the related costs. Of course, a lot depends on a specific case. In any case, it is risky to invest too much into requirements documentation without considering the price of the solution at the same time.
This results in a more iterative approach for preparing a contract, starting with an initial specification and bid and gradually improving both based on customer feedback.
However, it is not only about the customer side. We saw above that the commercial target is one of the most important project constraints. Hence, also in the internal view the specification (text) and an estimate (spreadsheet) go hand in hand. A specification cannot be seen as finished when there are no effort estimates for it. Developers should read requirements through the prism of their effort estimate and they should design solutions by taking into account their effort constraints beforehand.
Conclusion
Estimates for implementation of the requirements are very important in the software development process. They have impact during different stages:
- In the bidding phase the estimate is the basis for the price.
- During development the price (previously called an estimate) is one of the major constraints restricting design and development choices.
- The estimate is the basis for discussions between the technical and sales teams which leads to better understanding and alignment between them.
- It is essential to build estimation steps into the requirements development process to avoid bad surprises when a lot of effort has already been invested into analysis.
The author suggests thinking of the estimates as an integral part of the requirements, as an additional attribute. In such a view “estimated” can be seen as yet another important quality criteria for the requirements (in the aspect “agreement”).
References
- [1] IREB CPRE Foundation Level Syllabus: ireb.org/en/downloads/tag:syllabi
- [2] Steve McConnell, “Software Estimation: Demystifying the Black Art”, Microsoft Press, 2006.

Grigory Grin is a Chief Software Architect at Axinom – software supplier for Media- and In-Flight Entertainment solutions based in Germany and Estonia.
Grigory studied mathematics and graduated from the Ural State University in Russia in 1995. During his 25 years career on the software development field, Grigory had responsibilities in a broad range of roles – Development, Architecture, Business Analysis, Project Management. His main strengths are in alignment between the customer needs and contractors technical capabilities and solution portfolio to deliver the highest business value.
As a practitioner, Grigory has successfully led multiple multi-million euro projects for world-known brands in the aerospace industry with significant challenges on the field of Requirements Engineering.