










































































































































What are Big Data Projects?
When discussing the need for a “Big” Data Project, the first things that come to mind are some of the successes like “Moneyball” where a low ranked baseball team used statistics successfully to win big games. There are many examples of organizations that are successfully leveraging data in order to increase sales /revenues and cut costs.
Big Data has entered the common lexicon and terms such as Data Mining, Analytics, and Business Intelligence are being used by business and technology. Data provided by Google Trends indicate the increasing interest in Big Data.
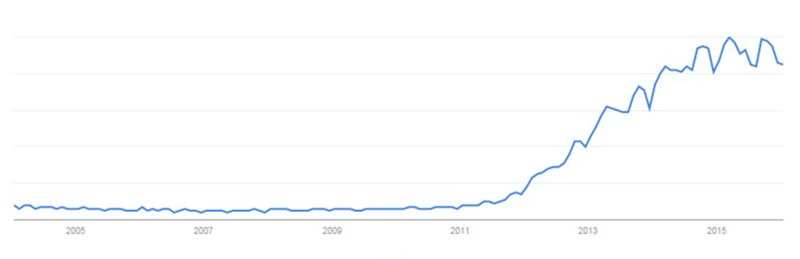
The following conclusions provided by Capgemini Big Data Survey and Information Magazine however are informative concerning the success of such projects.
- Spending on Big Data and Business Analytics is expected to increase and reach $41.5 billion
by 2018. - Only 13% of the organizations have achieved full scale production of their Big Data Implementations.
The analyst in charge of gathering requirements is burdened with high expectations. He or she is expected to deliver a project which will have startling business impacts.
However, what most organizations fail to take into account is the fact that very few Big Data Projects actually succeed due to a variety of reasons.
Definition of Big Data Project
The reason a project falls under the gamut of “Big Data” could be:
-
Huge volumes of data which conform to the definition of volume, velocity, and variety as required by a Big Data Project.
-
Use of new technologies such as:
Hadoop
Hadoop is an open-source software framework for storing data and running applications. It provides massive storage for any kind of data, enormous processing power, and the ability to handle virtually limitless concurrent tasks or jobs.
Teradata
Teradata is a data warehouse technology used to store large amounts of data. Teradata can load data actively and in a non-disruptive manner and, at the same time, process other workloads.
NoSQL
This technology was designed in response to a rise in the volume of data stored about users, objects and products, the frequency in which this data is accessed, and performance and processing needs. Traditional relational databases are not designed to cope with the scale and agility required by business.
The above are only examples of the technologies being used. There are always new and emerging technologies designed to support business needs. -
Multiple sources of data involved. The data is generated and stored in multiple systems across different geographies.
-
Big Data as an opportunity: Previously the data was ignored and members of the organization felt that it represented huge unexploited potential..
Understanding the motivation of calling a project a Big Data Project is important as it determines the need for the project and the nature of the results the business is expecting from the project.
Stakeholders of a Big Data Project
There are many stakeholders in a Big Data Project. The stakeholders include
- Customers
- Stockholders
- Management
- Members of the Project Team
- Data scientists
- Data architects
- Infrastructure teams
- External vendors
- Gate keepers for the data
- Domain Experts
- Technology Team
It’s likely that additional stakeholders will be “discovered” (identified) as the project progresses. Each has its own unique perspectives, requirements, and inputs. All must be considered.
The point of view of each category of stakeholders needs to be captured clearly and concisely. A good approach is having different requirement documents or clear sub-sections within the master requirements document for each category. In this manner requirements can be evolved, captured and kept track of. Note that individuals within each category of stakeholders are likely to have different views and interpretations. These should be resolved by the lead for each category. This will help greatly by achieving better communication and understanding amongst the participants.
Clearly Defined and Agreed Upon Business Objectives
Defining the Business Objectives in a Big Data project is an important first step.
In traditional projects there is a clearly defined business problem, for example, a loan process that needs automation or a new user interface to capture customer details. For Big Data projects the end objectives are vague. Business hopes to have a clear list of “actionable insights” post project implementation. However these insights need to be defined first.
To illustrate the success of data projects the case of a retail store is oft quoted.
By digging deeper into the Sales Data the store noticed that beer and diaper sales had a positive co-relation. By placing these items close to each other the store experienced a significant increase in sales of these items. Backed by such stories, management is willing to invest millions on Big Data project without a clear vision on the outcome. The analyst in charge of gathering requirement struggles because there is no clear understanding concerning what data fields need to be collected.
Would 25 data fields suffice for the project or are 250 required? What is the significance of a data field vis-à-vis another? Does the customer address need to be stored or is zip code sufficient?
A basic conundrum of a Big Data Project is whether to store all the data and try to identify patterns in the data or identify a few data fields based on the business objective. An experienced analyst should be able to manage expectations. One approach is to conduct multiple interviews with the stakeholders to clearly define the business needs and the problems to be solved post project implementation and to understand the data which will be required to address those business needs and source the required data fields.
The analyst has to boil down to the inputs received into a set of compelling results to be obtained post–project implementation, get buy in from all stakeholders, and then proceed with evolving the real requirements for the project.
Another good approach is to define and develop increments of functionality instead of adopting a big bang approach. This will lead to improved buy-in among various stakeholders and a better development approach because requirements can be refined as the project progresses. Business needs to understand what Big Data is capable of and it is the responsibility of the analyst to clearly explain to the stakeholders what will be achieved so that expectations are realistic.
Identify Team Members and Form the Team
A Big Data team typically consists of team members with expertise in data warehousing, business intelligence, data mining, statistics, and domain experts. Team members must have cross functional team management skills. It’s vital to ensure that data scientists and people with domain expertise are engaged.
According to McKinsey "…by 2018, the United States alone may face a 50 to 60 percent gap between supply and the requisite demand of deep analytic talent…”.
A good approach would be to foster Big Data skills in-house. This involves providing Big Data training to existing employees. There are a lot of on-line courses and other sources that can be leveraged for this purpose.
Engaging in team building activities and empowering team members to take responsibility and to make decisions will lead to better performance from the team.
Evolve the Real Requirements and a “doable” Project Approach
Big Data Projects are complex. Complexity arises from the fact that there are multiple data sources, many ways of storing data, and a large team with diverse skill sets and different backgrounds working on the project. There will be multiple approaches to a single task. So the first step is to break up the plan into smaller components aka a work breakdown structure (WBS). This way each task is broken down into a smaller portion, owners are assigned for each of these tasks, and it is easier to trace the progress of each of these tasks.
Sandbox Approach
Sandboxing is a good approach to ensure success of a Big Data project. Sandboxing involves an isolated computing environment. Instead of obtaining huge volumes of data in one go, it makes sense to get data from a single source. Then allow data scientists to manipulate the data, build models using the data, and understand the results being produced. This will help understand the data better, ensure that the right data is being sourced, and help decide on the technologies to be used when moving to large scale production.
The sandbox approach is a very effective method of ensuring that robust requirements are developed and will help evolve the requirements in an incremental manner. This approach will also help refine requirements.
Avoid Data for Data’s Sake
Many stakeholders and project sponsors continually demand more data and variety of data. The question to be asked is “What good is the data?”. Is having more data really going to solve the business problem or provide actionable insights? The moment business starts demanding more data or variety of data, it should raise a red flag in the analysts mind. The analyst needs to go back to the basics and ask the business what they are trying to achieve with the data. That way the right data can be collected instead of collecting huge volumes of data and not knowing what to do with it.
Identify and Address Unique Challenges of a Big Data Project
- Big Data projects are fundamentally different from other development projects and have a huge learning curve.
- Clear business and project objectives need to be defined.
- Special attention needs to be given to managing the expectations of stakeholders, based on the experience of similar projects.
- Training should be provided for the project manager and team members concerning how to undertake Big Data projects.
- Team members may be geographically separated. Experience has shown that this factor can jeopardize the project.
- There are unique complexities in managing Big Data projects that need to be addressed during project planning.
- There are implementation complexities that need to be identified and addressed.
- The data required to provide desired functionality is likely will be flawed or may not be available.
Evolving the Approach for Big Data Project
Complexity
Big Data Projects are complex by nature. Organizations generate vast amounts of data from various sources and it is difficult to correlate, cleanse and load the data. For each of these stages there are different tools and technologies.
Data travels from source to a staging area. After ensuring the data meets the desired quality, the next step is to move the data to a database. After this, various analytical tools are used to examine the data, create data models, or identify patterns in the data. This leads to huge amount of complexity and goes against the grain of an Information Technology adage which states that “for a project to be successful, complexity is best avoided”. In case of a Big Data Project, the organization must be willing to embrace complexity and understand how all of these individual parts come together in order to build a robust enterprise data architecture that is capable of meeting business needs.
Terminology and Technology
Another major reason for lack of success of Big Data projects is lack of the right skill sets. Big Data Projects are technologically complex. To help capture the requirements correctly, the analyst requires the help of a technology expert with experience in Database Technologies and a good understanding of data gathering, cleaning, and validation.
Terms like Database, Data Lakes, and Data Warehouse are easily confused. There are multiple new technologies involved and an analyst may find himself out of depth. In order to ensure the right requirements are captured, it helps to pair the analyst with a Subject Matter Expert (SME) or someone from technology with a strong background in data projects.
Strategy for Sourcing Data
Identification of data and data sources is the next step in defining the strategy to source the data. Data reside in multiple systems and in multiple formats across different geographies. Below are two templates that can be used for a data project and can be customized (“tailored”) based on project needs. These templates will help identify the number of data sources, data fields, regions from which data is being sourced, and the refresh rate of the data (daily/weekly/monthly).
Templates for sourcing the data
| Source Applications | Source Data Systems | Manual/Automatic Sourcing | Transformation Required | Number of Source Fields | Number of Target Fields | Regions Covered | Periodicity of the feed (Daily/Weekly/Monthly) |
Template to match the Business Problems to Data
| Business Problem/Question | Data required to solve the question | Data Sources | Data Owners | Data Collection Method | Type of Data | Data Security Required | Data Refresh Rate (Daily/Weekly/Monthly) |
Challenges in Dealing with Data
Figure 2 identifies the major challenges when dealing with data:

Entry Quality: Wrong data entering the system at the origin. This can result from either wrong data being available or human error at the time of data entry. This is one of the most common errors that occur in any organization and is very difficult to correct.
Process Quality: This happens as the data moves through the organization and is subject to multiple transformations. This can be remedied once the source of the data is identified.
Identification Quality: Not identifying a data field correctly or wrongly interpreting two similar data fields. This can be eliminated by identifying duplicates in the data.
Integration Quality: This refers to lack of completeness of data. In large organizations data exists in silos and it is difficult to get a complete picture. A single entity may have multiple pieces of data related to it scattered across the organization. For example, a customer applying for loan in a bank may also have huge deposits in some other branch, so the different pieces of information need to be integrated in order to give a complete picture of the customer.
Usage Quality: This happens when most of the data resides in legacy systems. Without subject matter experts, analysts have to understand the meaning and usage of data on their own.
Proper documentation of various data fields will help avoid this issue.
Aging Quality: In many organizations this is a major issue with data that is no longer valid. Determining if data is valid or not is the responsibility of the data owner.
Organizational Quality: Organization culture and processes have a lot of influence on the quality of dataand the availability of data. Business rules governing the data likely are not clearly defined or may be embedded deeply in the source code and hence difficult to interpret.
A good data strategy must identify the data quality problems, develop and provide techniques to overcome each challenge (“countermeasures”), implement them, monitor their effectiveness, and update the countermeasures as needed to overcome each data problem. This approach is considered a long term solution to capture the right data and ensure good quality data.
Strategy for Storing Data
The next step is interpreting the data stored in various sources and knowing what data will be received.
There are many ways to store data and there is “no one solution that fits all”. Companies need to understand the types and amount of data they have.
Some the questions that need to be considered are:
- Should some server space be requisitioned internally within the organization?
- Capacity of server space.
- Can data storage be out sourced?
- What Business Continuity Planning Process and Disaster Recovery process should be in place?
- What about record keeping and archival?
- What is the growth expected?
These questions can be resolved by having a robust Non-Functional Requirement (NFR) document which provides details regarding:
- Number of users
- Peak times for data access
- Service hours and availability
- Business Criticality
- Access Requirements
- Backup Requirements
- Archiving Requirements
Below are some of the storage options available. The infrastructure needs to be elastic and robust to meet business needs. A critical guideline is that business needs should drive the infrastructure and the technology tools being used, not the other way around.
Data Warehouses: This is a system used for reporting and data analysis. They act as a central repository for integrated data from various sources. The limitation of data warehouses is that they store data from various sources in some specific static structures and categories that dictate the kind of analysis that is possible on that data, at the very point of entry.
Data Lakes: A data lake is a hub or repository of all data that any organization has access to, where the data is ingested and stored in as close to the raw form as possible without enforcing any restrictive schema. This provides an unlimited window of view of data for anyone to run ad-hoc queries and perform cross-source navigation and analysis on the fly.
Data Hub: An enterprise data hub is a Big Data management model that uses a Hadoop platform as the central data repository. The goal of an enterprise data hub is to provide an organization with a centralized, unified data source that can quickly provide diverse business users with the information they need to do their jobs.
Understanding the differences between various storage options and keeping in mind the business needs will help decide on the best storage solution for the organization.
While evolving the requirements for a Big Data Project, exploring the above questions in depth will help define the set of needed stakeholders, the project and business objectives, the database technologies to be used, data sourcing issues, and the strategy for data storage, among many other areas.
Conclusion:
Given the hefty increase in spending on Big Data projects over the recent five-year period and the fact that only 13% of organizations have achieved full scale implementation, it’s vital that we evolve and improve the requirements approach to Big Data projects. This article identifies a set of factors that will improve the probability and extent of success of Big Data projects and asserts an improved project approach to undertaking them. As is the case for all projects, identifying and providing the “right” members of the project team, providing them appropriate training, and establishing an empowered team are critical.
References and Literature
- [1] Capgemini Data Management Survey 2015
- [2] Information Management Magazine (www.information-management.com).
- [3] Google Trends
- [4] International Data Corporation
- [5] McKinsey Big Data Survey

Ravishankar is a consultant with Financial Services division of Capgemini Financial Services with an overall experience of 13 years in the Banking and Financial Service sector. He has managed million dollar projects for Global Banking and Insurance companies and has advised clients in areas of Financial Risk & Regulation, Data Management, Analytics, Product Development and day -to-day operations.
He is a certified in Financial Risk Management (FRM), Project Management (PMP) and Data Mining (University of California) .In his spare time he enjoys conducting classes in Project Management and Business Analysis.