Chetan Arora
Ethics of Using LLMs in Requirements Engineering
Balancing Innovation and Responsibility in Leveraging LLMs in RE
In recent years, Large Language Models (LLMs) have gained significant traction across various domains due to their ability to process and generate human-like text. Their application in Requirements Engineering (RE) is particularly promising, offering the potential to (fully or partially) automate and enhance tasks such as requirements elicitation, specification, analysis, and validation [1]. By leveraging the vast amounts of data they are trained on, LLMs can assist in generating high-quality requirements, detecting ambiguities, negotiating requirements via LLM agents, and even predicting potential conflicts in requirements documents [1][7]. This advancement has the potential to revolutionise RE practices by improving efficiency, reducing human error, and enabling more scalable processes [1][3].
The integration of LLMs into RE, however, is not without its challenges. While the capabilities of LLMs are impressive, their use also raises a number of ethical concerns that must be carefully considered to ensure responsible and fair practices. Ethics, broadly speaking, is a normative philosophical discipline that deals with questions of right and wrong, as well as the principles that should guide human conduct [2]. Although there are scientific approaches to understanding moral behaviour - such as through psychology, neuroscience, or behavioural economics - this focus on describing or predicting moral behaviour rather than justifying what ought to be done. In the context of RE, integrating LLMs ethically requires attention to both normative principles (e.g., fairness, accountability) and empirical practices (e.g., how tools are used and misused in real-world settings). We recently conducted an extensive systematic review of the literature to identify the key ethical dimensions of LLMs or generative AI [4]. Our rigorous review process led to five key dimensions (privacy, transparency, bias, accountability and safety) that are most predominantly covered in the literature (covered below). While additional dimensions, such as human agency, oversight, and societal and environmental well-being, are highlighted in frameworks like the EU guidelines [5], they largely overlap with the five dimensions identified in our review. Moreover, aspects of human agency, oversight, and societal impact are inherently considered in RE practices, particularly in stakeholder involvement, regulatory compliance, and sustainability considerations. The following sections discuss these five ethical dimensions in detail, examining their implications for RE.
Ethical Dimensions of Using LLMs in Requirements Engineering
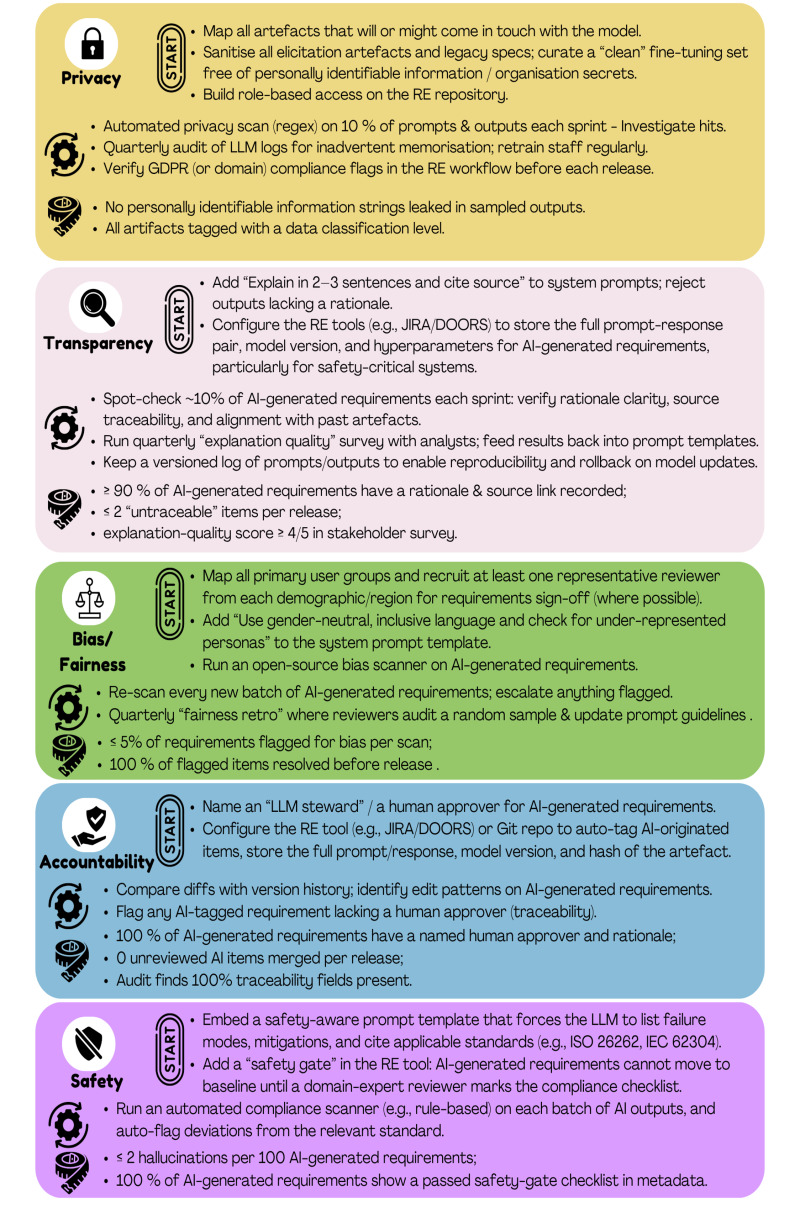
- Privacy - Requirements documents often contain sensitive information about a company’s operations, strategies, and user data. When LLMs are used to process or generate these requirements, there is a risk that this sensitive information could be exposed or misused. Ensuring that LLMs handle data in a way that maintains privacy and confidentiality is a critical ethical consideration. For instance, in domains with stringent data privacy rules, such as healthcare, if an LLM is used to generate requirements based on patient data - then the LLM inadvertently accesses unencrypted patient records, and there is a risk of exposing private health information.
- Transparency - LLMs often operate as "black boxes," producing outputs without providing clear insights into how these outputs were derived. This opacity can lead to mistrust and uncertainty among stakeholders who rely on the generated or analysed requirements. For instance, if a requirement seems misaligned with project goals, stakeholders need to understand how the LLM arrived at that conclusion to assess its validity to avoid similar mistakes by LLMs in the future.
- Bias - LLMs are trained on large datasets that often reflect the biases present in the data. When applied in RE, these biases can lead to the generation of biased or discriminatory requirements. For instance, if an LLM is trained on datasets that underrepresent certain groups, the requirements it generates may inadvertently exclude or disadvantage these groups, leading to non-inclusive or fair software.
- Accountability - Accountability is another key ethical dimension in the use of LLMs within RE. When LLMs are introduced, it becomes critical to clarify who is responsible for verifying the accuracy, relevance, and compliance of AI-generated requirements - since the model itself cannot be held accountable. This places renewed responsibility on RE teams to treat LLMs as assistive tools rather than autonomous agents.
- Safety - Safety in generative AI systems ensures these systems operate securely, minimising risks and issues. A key issue for safety is the hallucination tendency of LLMs, i.e., their likelihood of generating false information, links that do not exist and information that is not factually correct. This can be a major safety concern when using LLMs in RE.
Below, we detail the five ethical dimensions associated with employing LLMs in RE.
Privacy Concerns
There are several potential reasons for privacy issues in RE when using LLMs for automation. These arise due to the sensitive nature of data handled during the RE process, how LLMs function, and the practices around their training and deployment. Below are some examples of possible exposures:
- Exposure of Sensitive Data in Training Datasets: LLMs are often trained on vast datasets that may include proprietary, confidential, or personally identifiable information. If these datasets inadvertently contain sensitive data, the LLM may reproduce this data when generating requirements. Also, when using LLMs within organisational settings on projects with sensitive data, the datasets might unintentionally cross boundaries within an organisation in terms of access control.
- Unintentional Memorisation: LLMs may memorise specific data points from training or automation in case of retrieval-augmented generation (RAG) [3], such as sensitive information (e.g., names, addresses, business strategies), leading to unintended disclosure when generating outputs in the RE process.
- Inadequate Anonymisation: In an attempt to avoid privacy issues, the data in RE is often anonymised. However, if the sensitive data is not properly anonymised before being fed into LLMs, there is a risk that this data could be exposed or reconstructed by the model.
- Lack of Control Over Third-Party LLMs: Many organisations rely on third-party LLM services, such as those offered by cloud providers. If these external models are not sufficiently secure, or if data sent to them is not properly encrypted, it could lead to data leaks or breaches.
- Unclear Data Ownership and Usage Rights: When using third-party LLMs, there may be ambiguity over who owns the data being processed and how that data might be used (which is also related to the issue of accountability). Providers might sometimes retain the right to access or use the data for further model improvement, creating potential privacy concerns.
- Generation of Privacy-Invasive Requirements: LLMs might generate requirements that inadvertently violate user privacy, such as suggesting features that require excessive data collection or invasive tracking. This could lead to privacy issues if not carefully reviewed and adjusted by human analysts.
- Inadequate Access Controls: If proper access controls are not in place, unauthorised personnel may gain access to LLM-generated outputs, which could contain sensitive information. This lack of access control increases the risk of data leaks.
- Regulatory Non-Compliance: LLM usage may inadvertently lead to non-compliance with privacy regulations like GDPR, HIPAA, or CCPA. For example, the lack of a clear data deletion policy or improper handling of user consent can result in violations of data protection laws.
To mitigate privacy risks associated with LLMs in RE, one can attempt the following proactive strategies as a requirements analyst or at an organisational level. First, during requirements elicitation and specification, data sanitisation and controlled dataset curation should be enforced to prevent the inclusion of proprietary or confidential in requirement documents, stakeholder discussions, and historical project data used for LLM fine-tuning. At an organisational level, one should implement robust data access controls and encryption mechanisms to prevent unintended cross-boundary access to sensitive project data, and the requirements analysts and other stakeholders should be trained and made aware of data leakage or unintentional memorisation. There could be regular audits of model outputs to detect and filter out sensitive information and ensure proper data anonymisation. For organisations leveraging third-party LLM services, establishing strict contractual agreements and data protection policies can help clarify data ownership, retention policies, and usage rights to prevent unauthorised model training on proprietary data. On-premise or private cloud LLM deployments rather than public APIs can provide greater control over sensitive data, particularly when using LLMs for RE in safety-critical domains. Finally, aligning LLM usage with privacy regulations, such as GDPR, by embedding compliance checks within the RE workflow could help mitigate issues related to privacy when using LLMs in RE. By integrating these privacy-aware strategies into RE processes, organisations can responsibly leverage the power of LLMs while safeguarding sensitive information.
Transparency Concerns
- Poor Reasoning Capabilities of LLMs: LLMs are excellent pattern matchers but poor in reasoning [6]. They generate outputs based on statistical associations rather than logical inference or structured argumentation. In Requirements Engineering, this limitation becomes evident when LLMs produce requirements that appear misaligned with project goals or contradict existing constraints. Unlike human analysts, LLMs cannot reliably explain the rationale behind their suggestions or trace outputs back to specific stakeholder needs or regulatory clauses. Although recent research is exploring ways to improve reasoning and traceability in generative models, current LLMs still lack the capacity to support explainable, justifiable requirements - making human oversight essential to maintain trust and coherence in RE processes.
- Black-Box Nature of LLMs: LLMs are often called "black boxes," meaning that users do not easily understand their internal workings and decision-making processes. LLMs typically generate outputs without explaining or justifying their decisions. This can be problematic in RE, where understanding the reasoning behind each requirement is critical. For instance, an LLM might suggest a security-related requirement without explaining the underlying rationale (e.g., risk analysis or regulatory compliance).
- Difficulty in Tracing Sources: LLMs generate outputs based on patterns in the data they were trained on but do not provide explicit references or sources. In RE, traceability is a major concern, especially when they are based on regulations or stakeholder inputs. The inability to trace where the requirement comes from creates transparency issues and makes validation harder.
- Unrepeatable Outputs: LLMs such as GPT models have millions (or billions) of parameters that need tuning, making explanations of how they reach their decisions inherently difficult. The weights of parameters and the hyperparameter tuning of LLMs contribute to transparency issues, as different weights and tuning might lead to very different results. Hence, most of the outputs, once generated, might be difficult to reproduce, which might be essential in RE.
One of the best strategies to address transparency concerns in LLMs is always to generate a rationale for outputs or decisions [1]. Therefore, as a requirements analyst, instead of accepting requirements as-is, ask the LLM why it generated a particular requirement. It might also help to compare LLMs’ suggestions with past project requirements. For instance, if using LLMs to draft requirements, comparing the generated outputs with previous project requirements might be helpful in building confidence in the output. One of the key requirements in most projects is maintaining the traceability to the actual source of requirements, which can be a human (e.g., a product owner) or a project document. Hence, instead of accepting outputs without context, one should always ask for traceability to the source, and it can help track whether a requirement comes from best practices, regulations, provided documentation or inferred patterns. When using LLMs in RE processes, one can follow practices of storing the interaction or analysis session logs using LLMs and the model versions and hyperparameters used.
Bias/Fairness Concerns
- Historical and Social Biases in Datasets: LLMs are trained on vast datasets from the internet and other large-scale textual repositories. These datasets may contain inherent societal, cultural, or historical biases. When LLMs generate requirements, these biases may lead to discriminatory or unfair outputs, such as the exclusion of certain user groups or unequal representation in requirements intended to be universal. This can result in software failing to address diverse users' needs.
- Unintentional Reinforcement of Stereotypes: The linguistic choices made by the LLM when generating requirements could inadvertently reinforce societal stereotypes, such as associating certain professions with specific genders or making assumptions about user needs based on biased data patterns.
- Discriminatory Requirements Choices: Certain groups may be disproportionately disadvantaged if an LLM generates biased requirements. For example, a biased requirement might suggest that a software product should only be optimised for specific types of users (e.g., assuming all users are technically proficient or have high-speed internet access), thereby excluding less privileged groups. The exclusion of accessibility considerations or ignoring the needs of marginalised communities can be a significant bias concern when managing requirements using LLM-based agents, e.g., as an output of the requirements prioritisation, the design features that are more appealing to majority groups might be prioritised, neglecting the usability needs of others. Another example is that LLMs might suggest interface designs or language choices that are optimal for Western markets but not for users in other regions.
To mitigate concerns related to bias/fairness of using LLMs in RE, one should not solely rely on LLM-generated requirements and instead incorporate diverse stakeholder inputs from different demographics, regions, and expertise levels. It should be apparent from the offset who the main stakeholders or users of the system under development are to be able to analyse whether a given subgroup has been excluded. LLMs can be explicitly instructed to use gender-neutral or inclusive language in general. Another key aspect of ensuring fairness in requirements is to keep track of LLM-generated requirements or any modifications made to those requirements.
Accountability Concerns
- Unclear Responsibility for AI-Generated Requirements: When an LLM generates requirements, it’s unclear who is responsible if something goes wrong. In traditional RE, human analysts, stakeholders, or developers take responsibility for requirement decisions. However, suppose an LLM misinterprets stakeholder needs or suggests a faulty security requirement. In that case, it can be challenging to determine who should be held accountable - the data provider (e.g., the stakeholders that potentially provided faulty project data), the requirements analyst, or the product owner approving the requirement. This lack of clear accountability can create several ethical risks for organisations.
- No Clear Record of How AI-Generated Requirements Change: Traditional RE processes track requirement changes over time, ensuring that each version is reviewed and justified. With LLM-generated requirements, however, outputs may change unpredictably based on different prompts, model updates, or variations in training data. This makes it hard to track why a requirement changed, ensure consistency and review past versions unless the traditional processes are maintained with LLMs only used as assistants.
To mitigate accountability concerns, organisations must establish clear human oversight and maintain proper version control for AI-generated requirements. LLMs should serve as assistive tools rather than autonomous decision-makers, ensuring that LLM-generated requirements are reviewed, validated, and approved by a human analyst, product owner, or stakeholder before incorporation into project specifications. As mentioned earlier, LLMs should be prompted to provide justifications for their outputs, making tracing the reasoning behind requirements easier and facilitating human validation. To maintain a clear record of LLM-generated requirement changes, analysts should log all AI outputs in requirement management tools (e.g., JIRA, DOORS) or version control systems, e.g., Git.
Safety Concerns
- Risk of Generating Unsafe or Unverified Requirements: LLMs generate requirements based on patterns in training data but generally do not inherently assess the safety implications of their outputs. In safety-critical domains such as healthcare, aviation, autonomous vehicles, and industrial control systems, an LLM may suggest incomplete, ambiguous, or non-compliant safety requirements that fail to meet industry standards (e.g., ISO 26262 for automotive safety).
- Omission of Safety-Critical Constraints: LLMs might omit key safety constraints (e.g., redundancy mechanisms) when generating requirements, particularly if the training data does not sufficiently emphasise edge cases, failure handling, or emergency procedures. This can result in software vulnerabilities, unintended behaviours, or increased risks of hazardous failures in mission-critical systems.
To mitigate safety concerns, organisations must implement rigorous validation and review processes to ensure AI-generated requirements align with safety standards and industry best practices. Since LLMs do not inherently assess safety implications, human analysts should carefully review AI-generated requirements in safety-critical domains. Additionally, LLMs can be explicitly used with human oversight to enforce compliance with established safety standards such as ISO 26262 (automotive) within the requirements workflow. Furthermore, AI-assisted RE tools can incorporate predefined safety templates and structured prompts that explicitly require the model to consider failure scenarios, risk assessments, and safety constraints when generating requirements. By implementing manual validation checkpoints, automated compliance checks, and domain expert reviews, organisations can ensure that AI-generated requirements contribute to safe, reliable, and resilient software systems without compromising safety-critical factors.
Recommendations
Conclusion
Incorporating LLMs into RE presents both opportunities and challenges, particularly in terms of privacy, transparency, bias, accountability, and safety. While proactive strategies can help mitigate these concerns, RE remains a broader discipline that involves complex stakeholder interactions, evolving regulatory landscapes, and socio-technical considerations beyond those discussed in this article. Ethical implications in RE may extend to areas such as human oversight, sustainability, and long-term impact on software ecosystems, requiring ongoing research and adaptation. As LLMs continue to evolve, it is crucial for requirements analysts, organisations, and policymakers to work together to establish responsible AI practices that align with RE principles and ethical standards. Ultimately, the successful integration of LLMs in RE depends not only on technological advancements but also on timely human intervention to ensure fairness, compliance, and safety in software development.
References
- [1] Arora, C., Grundy, J., & Abdelrazek, M. (2024). Advancing requirements engineering through generative AI: Assessing the role of LLMs. In Generative AI for Effective Software Development (pp. 129-148). Cham: Springer Nature Switzerland.
- [2] Dewey, J., & Tufts, J. H. (2022). Ethics. DigiCat.
- [3] Arora, C., Herda T., & Homm V. Generating Test Scenarios from NL Requirements Using Retrieval-Augmented LLMs: An Industrial Study. 2024 IEEE 32nd International Requirements Engineering Conference (RE) (2024): 240-251.
- [4] Huang, Y., Arora, C., Houng, W. C., Kanij, T., Madulgalla, A., & Grundy, J. (2025). Ethical Concerns of Generative AI and Mitigation Strategies: A Systematic Mapping Study. arXiv preprint arXiv:2502.00015.
- [5] EU High-Level Expert Group on AI (2019). Ethics Guidelines for Trustworthy Artificial Intelligence, digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai. Last visited Sept 2025
- [6] Shojaee, P., Mirzadeh, I., Alizadeh, K., Horton, M., Bengio, S., & Farajtabar, M. (2025). The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity. ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf. Last visited Sept 2025
- [7] Zhang, X., Liu, L., Wang, Y., Liu, X., Wang, H., Ren, A., & Arora, C. (2023, September). Personagen: A tool for generating personas from user feedback. In 2023 IEEE 31st International Requirements Engineering Conference (RE) (pp. 353-354). IEEE.
Dr Chetan Arora is the Director of Education for the Software Systems and Cybersecurity Department and a senior lecturer in Software Engineering at Monash University, Australia. Dr Arora has more than 18 years of experience in industry and academia, focusing on responsible AI, trustworthy AI-driven systems, and compliance in software systems. He received his PhD from the University of Luxembourg (Luxembourg) and his Master's degree from Technische Universität, Kaiserslautern (Germany). He won the best PhD thesis award in the ICT domain at the University of Luxembourg.
Dr Arora is passionate about requirements engineering, software quality assurance, and applied AI research, with a primary focus on generative AI. His work spans various domains, including space systems, healthcare, finance and legal information systems. He has played a key role in bridging industry and academia through applied research initiatives, with several research outcomes adopted in practice. For instance, he worked in innovation management at SES Satellites in Luxembourg, focusing on applied AI and critical infrastructure (crisis) management across several EU/ESA projects. Dr Arora has co-authored more than 65 papers in international conferences and journals. He has won several best paper awards and is an active member of the International Requirements Engineering Board (IREB). More details here: [link: https://www.drchetanarora.com/ text: https://www.drchetanarora.com/ popup: yes].